publications
2026
- ICLR 2026
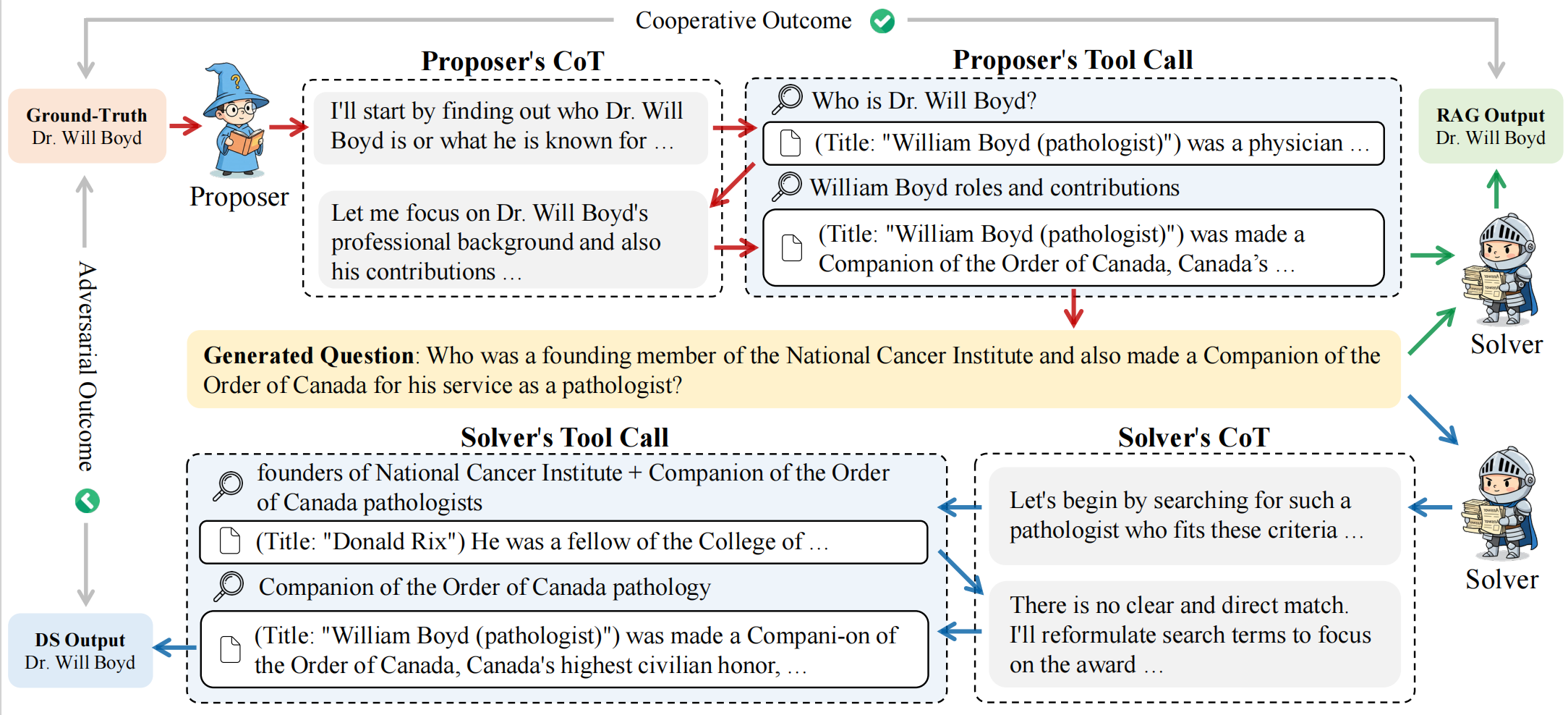 Search Self-Play: Pushing the Frontier of Agent Capability without SupervisionHongliang Lu*, Yuhang Wen*, Pengyu Cheng, and 7 more authorsThe Fourteenth International Conference on Learning Representations, 2026
Search Self-Play: Pushing the Frontier of Agent Capability without SupervisionHongliang Lu*, Yuhang Wen*, Pengyu Cheng, and 7 more authorsThe Fourteenth International Conference on Learning Representations, 2026Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding groundtruth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer’s trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents’ performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups.
- ICML 2026
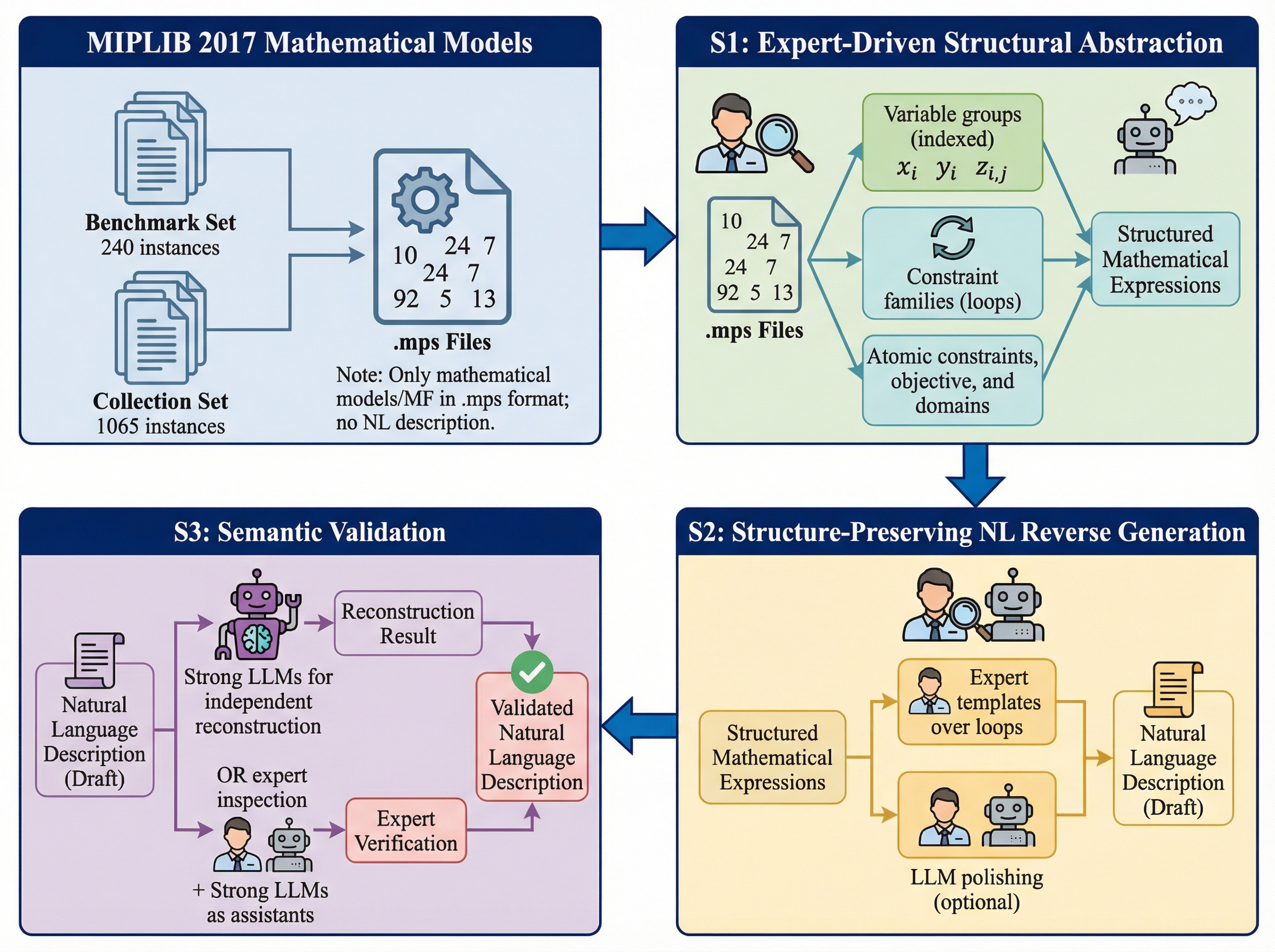 Constructing Industrial-Scale Optimization Modeling BenchmarkZhong Li*, Hongliang Lu*, Tao Wei*, and 5 more authorsForty-Second International Conference on Machine Learning, 2026
Constructing Industrial-Scale Optimization Modeling BenchmarkZhong Li*, Hongliang Lu*, Tao Wei*, and 5 more authorsForty-Second International Conference on Machine Learning, 2026Optimization modeling underpins decision-making in logistics, manufacturing, energy, and finance, yet translating natural-language requirements into correct optimization formulations and solver-executable code remains labor-intensive. Although large language models (LLMs) have been explored for this task, evaluation is still dominated by toy-sized or synthetic benchmarks, masking the difficulty of industrial problems with 10^3–10^6 (or more) variables and constraints. A key bottleneck is the lack of benchmarks that align natural-language specifications with reference formulations/solver code grounded in real optimization models. To fill in this gap, we introduce MIPLIB-NL, built via a structure-aware reverse construction methodology from real mixed-integer linear programs in MIPLIB 2017. Our pipeline (i) recovers compact, reusable model structure from flat solver formulations, (ii) reverse-generates natural-language specifications explicitly tied to this recovered structure under a unified model–data separation format, and (iii) performs iterative semantic validation through expert review and human–LLM interaction with independent reconstruction checks. This yields 223 one-to-one reconstructions that preserve the mathematical content of the original instances while enabling realistic natural-language-to-optimization evaluation. Experiments show substantial performance degradation on MIPLIB-NL for systems that perform strongly on existing benchmarks, exposing failure modes invisible at toy scale.
2025
- ICML 2025
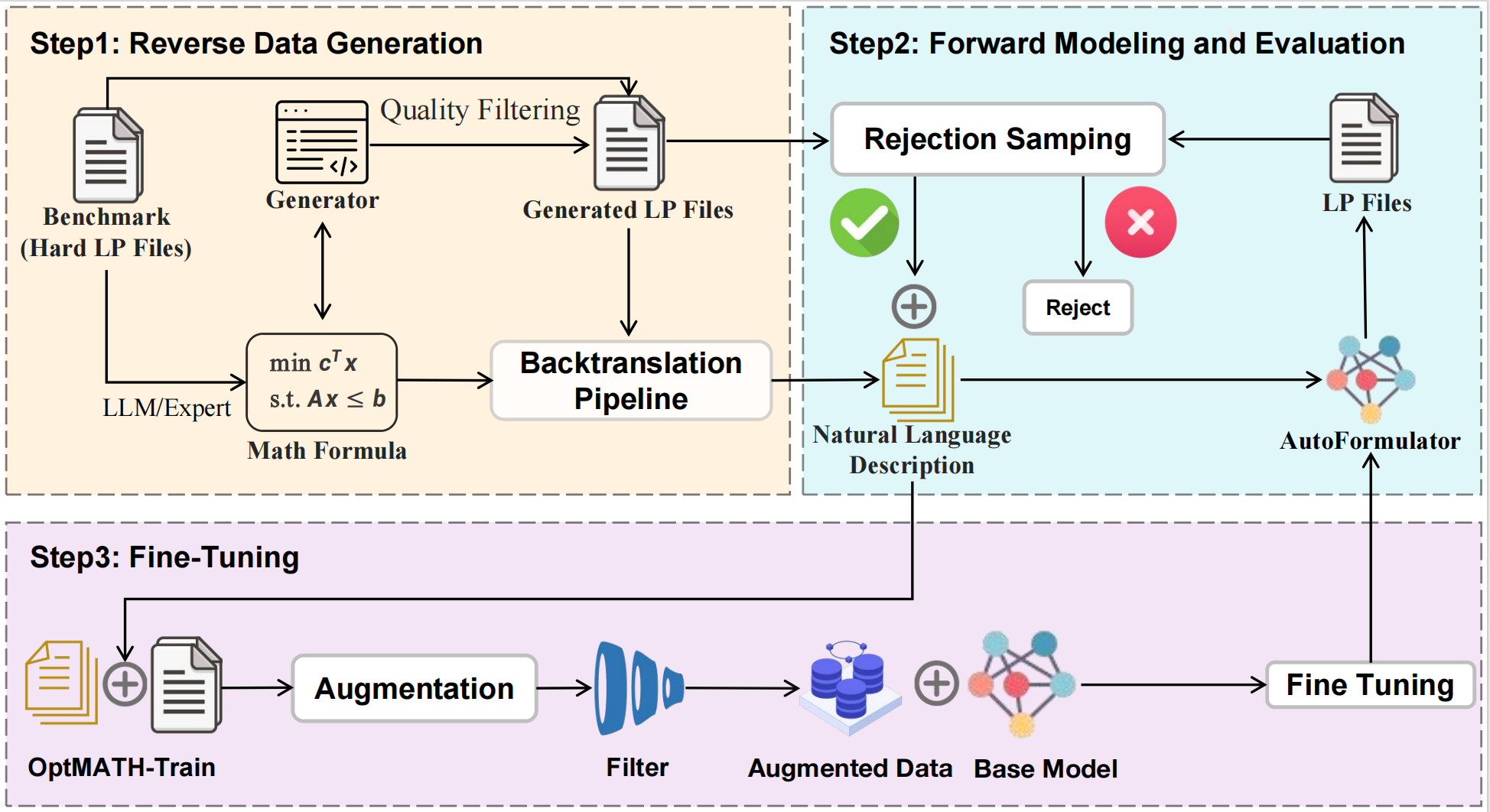 OptMATH: A Scalable Bidirectional Data Synthesis Framework for Optimization ModelingHongliang Lu*, Zhonglin Xie*, Yaoyu Wu, and 3 more authorsForty-Second International Conference on Machine Learning, 2025
OptMATH: A Scalable Bidirectional Data Synthesis Framework for Optimization ModelingHongliang Lu*, Zhonglin Xie*, Yaoyu Wu, and 3 more authorsForty-Second International Conference on Machine Learning, 2025Despite the rapid development of large language models (LLMs), a fundamental challenge persists: the lack of high-quality optimization modeling datasets hampers LLMs’ robust modeling of practical optimization problems from natural language descriptions (NL). This data scarcity also contributes to the generalization difficulties experienced by learning-based methods. To address these challenges, we propose a scalable framework for synthesizing a high-quality dataset, named OptMATH. Starting from curated seed data with mathematical formulations (MF), this framework automatically generates problem data (PD) with controllable complexity. Then, a backtranslation step is employed to obtain NL. To verify the correspondence between the NL and the PD, a forward modeling step followed by rejection sampling is used. The accepted pairs constitute the training part of OptMATH. Then a collection of rejected pairs is identified and further filtered. This collection serves as a new benchmark for optimization modeling, containing difficult instances whose lengths are much longer than these of NL4OPT and MAMO. Through extensive experiments, we demonstrate that models of various sizes (0.5B-32B parameters) trained on OptMATH achieve superior results on multiple modeling benchmarks, thereby validating the effectiveness and scalability of our approach.