最后更新: 2026-05-15
1. 概述
On-Policy Distillation (OPD) 是一种把 on-policy 训练 和 知识蒸馏 合在一起的后训练范式:训练时不再只让 student 模仿 teacher 预先写好的答案,而是先让 student 按当前策略自己生成,再让 teacher 在这些 student-generated trajectories 上提供 dense feedback。
一句话说:
OPD的本质不是“student 抄 teacher 的标准答案”,而是“student 先按自己会走的路走一遍,teacher 再在这条路上的每个状态给纠偏信号”。
1.1 传统知识蒸馏在做什么
传统知识蒸馏的基本目标,是把一个大 teacher $\mathcal T$ 的预测分布迁移到一个更小的 student $\mathcal S$ 上。它不是只让 student 学 hard label,而是让 student 学 teacher 对整个候选空间的 soft probability distribution。Hinton KD 把这种隐藏在概率分布里的相对关系称为 dark knowledge:例如 teacher 不只告诉 student 下一个 token 最可能是 car,还会通过概率分布告诉它 automobile 比 apple 更接近正确答案。12
| 给定模型输出的 pre-softmax logits $z \in \mathbb{R}^{ | V | }$,其中 $ | V | $ 是词表大小,KD 先用 temperature $\tau$ 把 logits 变成 softened distribution: |
$\tau$ 越大,分布越平滑,teacher 的次优 token 概率也会被显露出来。标准 KD 目标是在同一个输入上下文 $x$ 上,让 student 的 softened distribution $p_\theta$ 匹配 teacher 的 softened distribution $p_T$:
\[\mathcal{L}_{\mathrm{KD}} = \tau^2 D_{\mathrm{KL}} \left( p_T(\cdot|x;\tau) \,\|\, p_\theta(\cdot|x;\tau) \right).\]这里的 $\tau^2$ 是为了抵消高温 softmax 带来的梯度缩小,使 KD loss 和 hard-label cross entropy 在联合训练时保持相近量级。当 $\tau \to \infty$ 时,KD 的梯度近似变成12
\[\frac{\partial \mathcal{L}_{\mathrm{KD}}} {\partial z_i^{\mathcal S}} \approx \frac{1}{|V|} \left( z_i^{\mathcal S} - z_i^{\mathcal T} \right),\]所以高温极限下,KD 近似等价于让 student 拟合 teacher 的 raw logits,也就是一种 logits MSE。直觉上,这会强迫 student 复制 teacher 的整个 logit geometry,而不是只复制 top-1 token。
放到 autoregressive language modeling 里,输入上下文不再只是一个静态 $x$,而是每一步的 prefix:
\[(x,y_{<t}).\]因此传统 KD 最常见的形式是 token-level KD:在数据集或 teacher 轨迹给定的 prefix 上,逐 token 匹配 teacher 和 student 的 full-vocabulary distribution:
如果不想在每一步保存或查询 teacher 的完整 logits,也可以做 sequence-level KD:先让 teacher 用 beam search / sampling 生成一条完整答案 $\hat y$,再把这条 teacher-generated sequence 当作 pseudo label,让 student 做普通 NLL / SFT:3
这两类传统方法的优点都很明确:训练稳定,监督信号 dense,token-level KD 还能利用 teacher 的完整 soft distribution,sequence-level KD 则更便宜、更接近普通 SFT。但按照 survey 的范式看,它们有一个共同前提:训练 prefix 来自 $\mathcal D$ 或 teacher 预先生成的静态轨迹,而不是 student 自己当前策略会访问到的 prefix。
也就是说,传统 KD 更像“老师在黑板上写满分答案,学生在下面抄”。学生确实能看到每一步标准解,也能学习 teacher 的 soft preference,但它没有在自己写偏后的 prefix 上接受纠偏。这就是后面 OPD 要解决的核心错位:传统蒸馏主要解决的是分布怎么匹配,OPD 进一步想要解决的是应该在哪些 student-visited states 上匹配。
1.2 传统蒸馏的核心缺点
1. Exposure bias:训练时看 teacher prefix,推理时看 student prefix
自回归模型的状态就是当前 prefix:
\[s_t=(x,y_{<t}).\]传统 SFT / KD 训练时,$s_t$ 大多来自人类答案、teacher 答案或固定数据集;但推理时,$s_t$ 来自 student 自己刚刚生成的 token。只要 student 早期犯一个小错,它后面就会进入 teacher 数据里很少出现的 prefix state。24
这就是 exposure bias / train-test mismatch:
- 训练时监督的是 $d_{\mathcal D}(s)$ 或 $d_{\pi_T}(s)$;
- 推理时真正遇到的是 $d_{\pi_\theta}(s)$;
- 两个状态分布越不一致,student 越容易在自己走偏后的状态里没有纠错能力。5
这也是 GKD / OPD 这条线最核心的问题意识:不是 teacher 不强,而是 teacher 教的状态不一定是 student 真正会遇到的状态。6
2. Compounding error:小错误会沿着长序列放大
在短文本任务里,teacher forcing 的问题可能不明显;但在长链推理、代码、工具调用、多轮 agent 任务里,一个早期错误会改变后面全部上下文。DAgger 的模仿学习分析里,这类纯 teacher-forcing / behavior cloning 的误差会随 horizon 出现 $O(\epsilon T^2)$ 级别的累积;survey 也把这个结论作为 OPD 的核心理论动机。52
例如数学推理里,student 第一步把变量关系写错,后面每一步都在错误前提上继续推。传统 KD 通常只在标准解路径上教它“正确轨迹是什么”,却没有在 student 自己的错误轨迹上教它“从这里开始哪里不对”。
所以 off-policy 蒸馏的问题不是简单的“数据不够多”,而是监督位置错了:它密集地监督了 teacher 会访问的状态,却稀疏甚至完全没有监督 student 真实会访问的错误状态。6
3. Mode averaging:小 student 被迫覆盖 teacher 的太多模式
如果用 forward KL:
\[D_{\mathrm{KL}}(\pi_T\|\pi_\theta),\]训练会特别在意 teacher 高概率但 student 低概率的位置。这有利于覆盖 teacher 的多种可能输出,但当 student 容量明显小于 teacher 时,它可能被迫在多个 mode 之间“平均化”:每条路都学一点,但没有一条路真正稳定。27
这也是 MiniLLM 强调 reverse KL 的原因:对 reasoning distillation 来说,小模型往往更需要先学会 teacher 的一个高质量主模态,而不是平均覆盖所有可能写法。78
4. Teacher trajectory 不等于 student 最需要的训练样本
teacher 生成的答案通常太完美,恰好避开了很多 student 会犯的低级错误。可是 student 最需要的监督,往往就在这些“弱模型容易犯错”的边界状态附近。69
因此,传统离线蒸馏容易出现一种错位:
- teacher 给的是高质量答案;
- student 需要的是在自己能力边界附近的纠偏;
- 训练很密,但不一定教到了最该教的位置。
1.3 那直接做 RL 行不行?
RL 正好解决了状态分布问题:student 自己 rollout,所以训练数据来自 $d_{\pi_\theta}(s)$。但 RL 的问题在另一端:reward 通常太 sparse。例如 RLVR / GRPO 里,一条长推理最后只有一个 outcome reward:
这会导致 credit assignment 很粗:
- 答案错了,不知道是哪一步开始错;
- 一组 rollout 全错时,组内 advantage 可能接近失效;
- 对长链 reasoning / agent trajectories,单个 outcome reward 很难稳定指导中间 action。
所以可以把 SFT/KD 和 RL 的优缺点压成一张表:
| 方法 | 采样分布 | 监督密度 | 主要问题 |
|---|---|---|---|
SFT / SeqKD | teacher / dataset 轨迹 | dense | exposure bias,student 错误状态上没监督 |
Token-level KD | fixed prefix 或 teacher prefix | dense | 仍然 off-policy,且常有 tokenizer / full-logit 成本 |
RL / RLVR | student 自己 rollout | sparse | credit assignment 难,sample efficiency 低 |
OPD | student 自己 rollout | dense | 需要可靠 teacher / logprob scorer |
1.4 OPD 的核心想法
On-Policy Distillation(OPD,在线策略蒸馏) 的出现,就是为了同时做到:
- 像 RL 一样,让 student 在自己真实会访问到的状态上学习;
- 像 KD 一样,让 teacher 提供逐 token / 逐 step 的 dense supervision。
OPD 可以统一表示为如下的数学形式:2
\[\mathcal{L}_{\mathrm{OPD}}(\theta) = \mathbb{E}_{y\sim\pi_{\mathrm{mix}}} \left[ \sum_{t=1}^{|y|} \mathcal{D}_f \left( p_T(\cdot|x,y_{<t}), p_\theta(\cdot|x,y_{<t}) \right) \right].\]这里有两个核心变量:
- $\pi_{\mathrm{mix}}$:behavior policy,决定训练时使用哪些 trajectory / prefix state(数据从哪儿来,人工标注,teacher生成,student生成);
- $\mathcal{D}_f$:来自 $f$-divergence family 的分布距离,决定在每个 prefix 上如何让 student 对齐 teacher。
其中 $f$-divergence 的一般形式是:
\[D_f(P\parallel Q) = \mathbb{E}_{x\sim Q} \left[ f\left( \frac{P(x)}{Q(x)} \right) \right],\]其中 $f$ 是凸函数,且 $f(1)=0$。在 OPD 里通常把 $P$ 看成 teacher distribution,把 $Q$ 看成 student distribution;但具体方法可能交换 teacher/student 的位置,所以用 $\mathcal{D}_f(P,Q)$ 这种双参数写法,而不是固定写成 $D_f(P\parallel Q)$。常见选择如下面张表所示:
| 散度 | $f(u)$ / 形式 | 训练偏好 | 适合直觉 |
|---|---|---|---|
| Forward KL | $f(u)=u\log u$,得到 $D_{\mathrm{KL}}(P\parallel Q)$ | mode-covering / zero-avoiding | teacher 觉得可能的地方,student 都要覆盖 |
| Reverse KL | $f(u)=-\log u$,得到 $D_{\mathrm{KL}}(Q\parallel P)$ | mode-seeking / zero-forcing | student 更集中到 teacher 支持的高质量模式 |
| JSD10 | 对 $M=\frac{1}{2}(P+Q)$ 分别算 KL 后取平均 | 有界、较稳定,折中覆盖与收缩 | 比 KL 更温和,常用于稳定训练 |
| TVD | $f(u)=\frac{1}{2}u-1$ | 关注最大概率差异,鲁棒但不光滑 | 理论上常见,神经网络里直接优化较少 |
所以常见的 OPD 算法设计可以从三个维度来看:
- 采样谁的轨迹:dataset / teacher / student / mixture;
- 在哪个粒度上监督:token-level full-vocab divergence、sampled-token logprob、sequence-level reward;
- 用什么 divergence 对齐:forward KL、reverse KL、JSD、skewed KL 或其他 $f$-divergence。
1.5 OPD为什么重要
OPD 的价值不只是“又一种蒸馏 loss”,而是把 LLM post-training 里的三个目标连了起来:
- 压缩强 teacher:teacher 已经通过 RL 或昂贵 post-training 学到强策略,student 不必重新走一遍高成本探索;
- 降低 RL 成本:相比 sparse outcome reward,teacher logprob 能提供 dense token-level credit;
- 缓解 exposure bias:训练发生在 student 自己的 rollout 分布上,而不是只在 teacher 轨迹上 teacher forcing。
这也是为什么近一年的技术报告和方法论文都在不同方向扩展 OPD:
-
Qwen3 / MiMo / Nemotron /GLM-5/Deepseek V4把 OPD 用作工业级 post-training 和多领域能力整合; -
GOLD解决跨 tokenizer / 跨模型家族问题; -
OPSD / RLSD研究没有外部 teacher 时如何做 self-distillation; -
OpenClaw-RL把 OPD 推向多轮 agent 场景,用下一状态反馈构造 hindsight teacher signal。
2. 论文总结
腾讯的这篇survey2把OPD相关的工作按不同维度进行了分类总结:
- 作者: Mingyang Song, Mao Zheng (Tencent)
- 发表时间: 2026-04
- 论文: https://arxiv.org/abs/2604.00626
- 核心贡献:
- 首篇专门针对 On-Policy Distillation 的综述
- 提出三维分类法:feedback signal、granularity、training paradigm
- 系统梳理了 f-divergence 目标函数家族
- 覆盖最新的所有重要工作
- 统一目标形式:
Survey 的价值是把各类方法放进同一个坐标系:差别主要来自 state distribution 是否 on-policy、teacher 能访问什么信息、监督是 full-vocab / sampled-token / sequence-level、以及 $\mathcal{D}$ 选 forward KL、reverse KL、JSD 还是其他变体。
- 推荐: 入门 OPD 领域的最佳起点
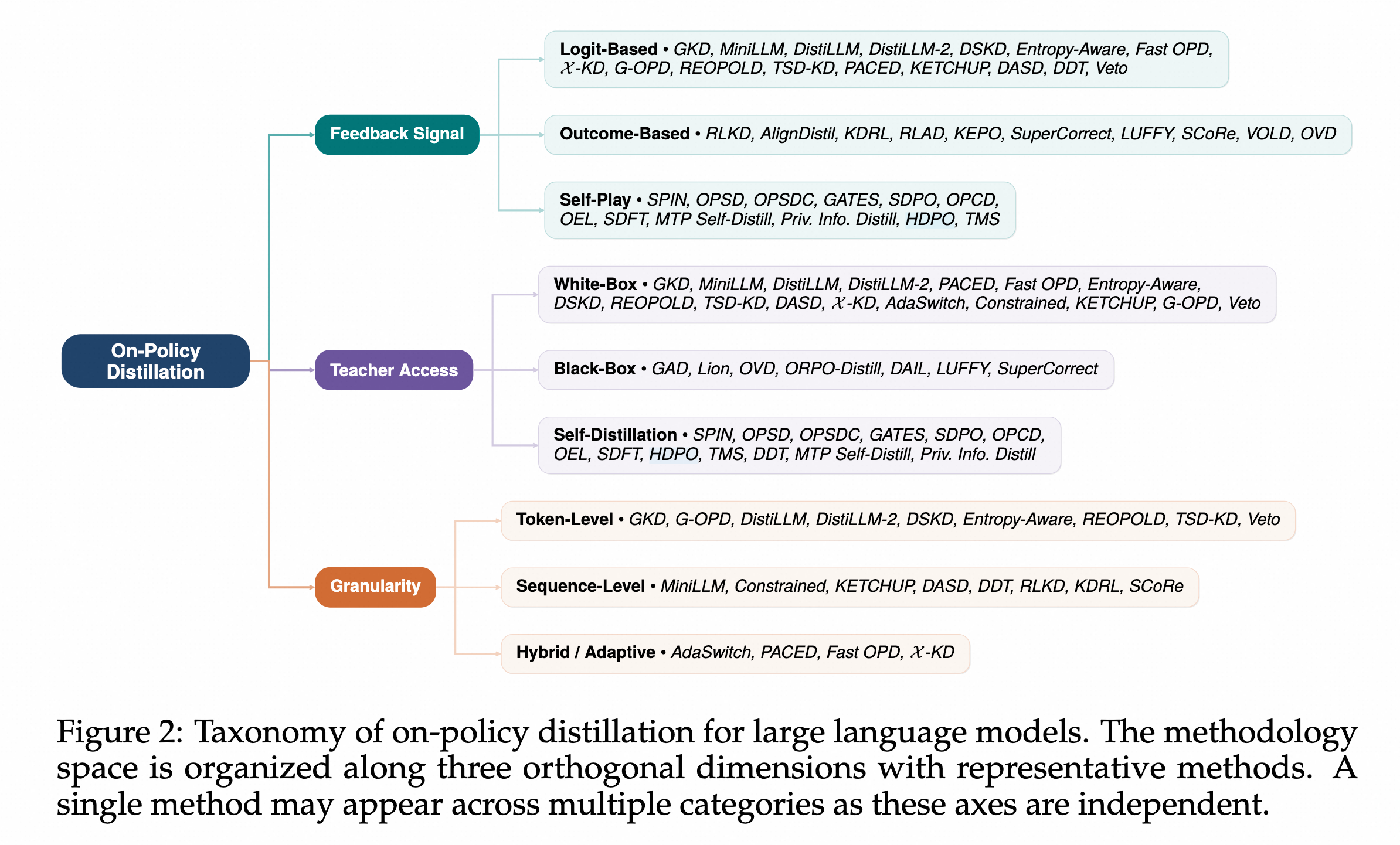
下面挑选一些个人觉得重要的工作进行简要介绍。
2.1 奠基性工作
这条线最早的两个奠基工作可以理解成 OPD 的两种 loss 计算范式。更详细的公式推导见 OPD数学原理:两种 loss 计算方式。
GKD: state on-policy + full-vocab divergence
- 论文: On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes6
- 作者: Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, Olivier Bachem
- 发表时间: ICLR 2024
- 核心贡献: 把训练 prefix 从固定数据 / teacher trajectory 推到 student 自己会访问的 prefix,并允许在 off-policy 和 on-policy 数据之间做 mixture。
GKD 原文的目标函数可以先写成下面这个 mixture objective:
\[\mathcal{L}_{\mathrm{GKD}}(\theta) = (1-\lambda) \mathbb{E}_{(x,y)\sim\mathcal D} \left[ \sum_{t=1}^{|y|} D \left( p_T(\cdot|x,y_{<t}), p_\theta(\cdot|x,y_{<t}) \right) \right] + \lambda \mathbb{E}_{x\sim\mathcal D,\, \tilde y\sim \operatorname{sg}[p_\theta(\cdot|x)]} \left[ \sum_{t=1}^{|\tilde y|} D \left( p_T(\cdot|x,\tilde y_{<t}), p_\theta(\cdot|x,\tilde y_{<t}) \right) \right].\]这里 $\lambda$ 控制 off-policy 数据和 on-policy student rollout 的混合比例:
- $\lambda=0$:退回传统 off-policy KD,只在 dataset / teacher prefix 上做蒸馏;
- $\lambda=1$:完全使用 student 自己生成的 prefix,也就是纯 student-rollout OPD;
- $D$ 可以取 Forward KL、Reverse KL 或 JSD。
| 值得注意的是第二项:$\tilde y$ 确实由 student 当前策略 $p_\theta(\cdot | x)$ 采样,但这里写成 $\operatorname{sg}[p_\theta]$,表示 sampling path stop-gradient。也就是说,GKD 不对“采样出 $\tilde y$ 这件事”做 REINFORCE / policy-gradient 反传;$\tilde y$ 只是被当作一条训练样本,用来构造 student 自己会访问到的 prefix state: |
所以 GKD 的关键不是“只看 student 采样出的 token”,而是:student rollout 只负责产生 prefix state,真正的 loss 仍然是在这些 prefix 上做 full-vocabulary distribution matching。 如果只看纯 on-policy 部分,可以简写为:
\[\mathcal{L}_{\mathrm{GKD}}(\theta) = \mathbb{E}_{x} \mathbb{E}_{\tilde y\sim \operatorname{sg}[p_\theta]} \left[ \frac{1}{T} \sum_{t=1}^{T} D \left( p_T(\cdot|\tilde s_t), p_\theta(\cdot|\tilde s_t) \right) \right].\]如果选择 Forward KL,单步 loss 等价于 full-vocab soft-label cross entropy:
\[L_t^{\mathrm{fwd}} = - \sum_a p_T(a|\tilde s_t) \log p_\theta(a|\tilde s_t),\]对应梯度是:
\[\nabla_\theta L_t^{\mathrm{fwd}} = - \sum_a p_T(a|\tilde s_t) \nabla_\theta \log p_\theta(a|\tilde s_t).\]这里的关键点是:梯度会看完整词表 $a\in V$,而不是只看 student 实际采样出来的 $\tilde y_t$;同时梯度不会穿过 $\tilde y\sim p_\theta$ 的采样过程。 因此 GKD 的 on-policy 性体现在 state distribution 上;梯度更新本身仍然更像 supervised KD,所以信号 dense、方差低、训练稳定。
MiniLLM: action on-policy + sequence-level Reverse KL
- 论文: MiniLLM: On-Policy Distillation of Large Language Models7
- 作者: Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
- 发表时间: ICLR 2024
- 代码: https://github.com/microsoft/LMOps/tree/main/minillm
- 核心贡献: 从 sequence-level Reverse KL 出发,把 OPD 写成 policy-gradient / REINFORCE 形式,用 teacher/student logprob ratio 构造 reward-to-go。
MiniLLM 的出发点不是在每个 prefix 上算 full-vocab divergence,而是直接最小化 student sequence distribution 到 teacher sequence distribution 的 Reverse KL:
\[\min_\theta L_{\mathrm{seq\text{-}rev}}(\theta)=\min_\theta D_{\mathrm{KL}}\!\left( \pi_\theta(\cdot|x)\,\|\,\pi_T(\cdot|x) \right) =\min_\theta \mathbb{E}_{y\sim\pi_\theta(\cdot|x)} \left[ \log \pi_\theta(y|x)-\log \pi_T(y|x) \right].\]论文通过推导,sequence-level Reverse KL 的梯度可以写成:
\[\nabla_\theta L_{\mathrm{seq\text{-}rev}} = - \mathbb{E}_{y\sim p_\theta} \sum_{t=1}^{T} \left( R_t-1 \right) \nabla_\theta \log p_\theta(y_t|s_t).\]其中
\[R_t = \sum_{t'=t}^{T} \log \frac{ p_T(y_{t'}|s_{t'}) }{ p_\theta(y_{t'}|s_{t'}) }.\]这里的关键点是:student 采样出来的 token 本身就是 policy action,梯度更新只沿着 sampled trajectory 走,并用 $R_t-1$ 作为 advantage/reward 权重。 如果 teacher 比 student 更认可这条后续轨迹,$R_t$ 大,梯度会提高对应 sampled token 的概率;反之就压低。它更接近 RL,所以能直接优化 sequence-level mode-seeking 目标,但方差更高,需要 teacher-mixed sampling、baseline、length normalization 等稳定化技巧。
两个奠基工作的本质区别
| 维度 | GKD-style | PG-style |
|---|---|---|
| on-policy 体现在哪里 | student rollout 产生 prefix state | student sampled token 同时进入 policy-gradient |
| 是否对采样路径求导 | 否,rollout 通常 stop-gradient | 是,用 score-function / REINFORCE |
| 单步训练信号 | full-vocab divergence | sampled-token reward / sequence reward-to-go |
| teacher 需要提供什么 | 当前 prefix 下完整 logits / token distribution | sampled token 的 teacher logprob,完整版本需要 token logprob 序列 |
| 梯度更新对象 | 每个 prefix 上更新整个词表分布 | 只沿 sampled trajectory 更新被采样 token |
| 方差和稳定性 | 更像 supervised KD,dense、低方差、稳定 | 更像 RL,稀疏一些、高方差、需要稳定化 |
| 适合直觉 | “student 自己走到状态,然后在这些状态上做 full-vocab KD” | “student 自己采样动作,然后用 teacher/student logprob ratio 构造 advantage” |
所以,二者都叫 on-policy distillation,但“on-policy”发生的位置不一样:
- GKD 是 state on-policy:student 负责走到自己的 prefix state,teacher 在这些 state 上给 full-vocab 分布监督。
- MiniLLM 是 action / trajectory on-policy:student 采样出的 token 本身进入 policy-gradient,teacher 的 logprob ratio 直接决定这条 sampled action 是被加强还是被压低。
2.2 重要进展
这一节按发表时间从早到晚排序。
On-Policy Distillation — Thinking Machines Blog
- 作者: Thinking Machines Lab
- 发表时间: 2025-10-27
- 博客: https://thinkingmachines.ai/blog/on-policy-distillation/ 11
- 代码: https://github.com/thinking-machines-lab/tinker-cookbook/tree/main/tinker_cookbook/recipes/distillation
- 范式定位: PG-style / sampled-token OPD。它不算 full-vocab KL,而是让 teacher 在同一条 student trajectory 上对 sampled token 计算 logprob,再把
teacher_logprob - student_logprob当作 per-token advantage,接现有 RL importance-sampling loss。 - 核心贡献:
- 用很清晰的工程视角重新定义 OPD:student 自己 rollout,teacher 不重新生成答案,只在同一条 student trajectory 上逐 token 计算 logprob。
- 将 OPD 放在
SFT / distillation和RL中间:既保留 on-policy state distribution,又获得 dense token-level supervision。 - 展示 OPD 在 reasoning、personalization、continual learning 中的作用,尤其强调它可以用较低成本恢复或压缩 post-training 行为。
- 关键目标 / Loss:

实现上可以直接把 teacher/student logprob gap 变成 sampled-token advantage:
\[A_t^{\mathrm{OPD}} = \log \pi_T(y_t|s_t) - \log \pi_\theta(y_t|s_t), \qquad \mathcal{L}_{\mathrm{OPD}} = - \mathbb{E}_{\hat y\sim\pi_\theta} \sum_t \mathrm{sg}[A_t^{\mathrm{OPD}}] \log \pi_\theta(y_t|s_t).\]这篇 blog 的价值在于把 OPD 讲成一个可落地 recipe:teacher 不是 rollout policy,而是 student trajectory 上的 process-level scorer。它更像 MiniLLM-style 的工程化简化版:保留 sampled-token reverse-KL 信号,但直接复用 RL 框架的 importance-sampling / PPO-like 更新,而不是追求 full-vocab distribution matching。
- 重要性: 它是 2025 年 OPD 重新受到关注的重要传播节点,也把 OPD 和 RL 工程管线连接得非常清楚。
GOLD: Unlocking On-Policy Distillation for Any Model Family
- 作者: HuggingFace H4 Team
- 发表时间: 2025-10-29
- 论文/博客: https://huggingface.co/spaces/HuggingFaceH4/on-policy-distillation 12
- 范式定位: GKD-style 的跨 tokenizer 扩展。GOLD 继承 GKD/GKDTrainer 的 on-policy/off-policy scheduling,核心仍是 logit/distribution distillation;它的新问题是 teacher 和 student tokenizer 不同,不能直接逐维 KL。
- 核心贡献:
- 提出 General On-Policy Logit Distillation (GOLD)
- 解决跨模型家族蒸馏的 tokenizer 不兼容问题:这是计算 KL 时的一种近似方法,并不完全精确
- 证明 OPD 方法对多种模型架构普遍有效
- 关键目标 / Loss:
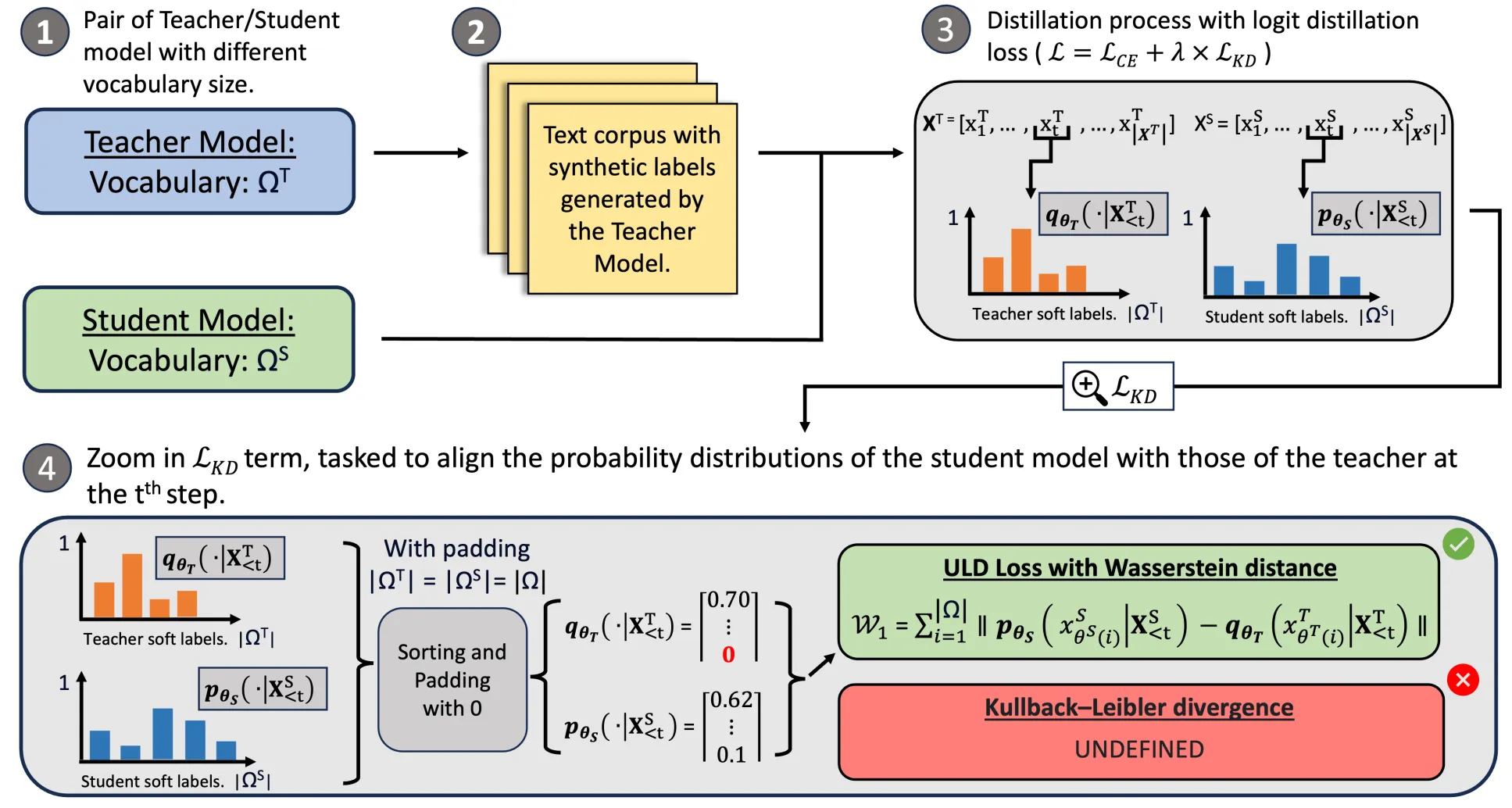
其中 mapped token 用语义可对齐的 GKD/KL loss,无映射 token 才退回 ULD 的排序近似。跨 tokenizer 序列对齐时还用自回归链式法则合并 token:
\[\log p(t_{i:j}|s) = \sum_{k=i}^{j} \log p(t_k|s,t_{i:k-1}).\]GOLD 的贡献不是换一个 KL,而是让不同 tokenizer / model family 之间也能近似做 GKD-style OPD。mapped token 部分仍然是标准 logit KL / GKD loss;unmapped token 才退回 ULD 的排序近似。因此它不是 PG-style,不用 sampled-token advantage 来绕开词表问题,而是努力把 full/logit-level distillation 的对齐条件补回来。
- 重要性: 解决了实际应用中 teacher/student 来自不同模型家族时的关键障碍
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
- 作者: Siyan Zhao et al.
- 发表时间: 2026-01 (被引 16+)
- 论文: https://arxiv.org/abs/2601.18734 13
- 范式定位: GKD-style 的 self / privileged-information 版本。student 先 rollout,但 teacher 在每个 student prefix 上输出 full-vocabulary distribution;论文实验还明确显示 full-vocab logit distillation 优于 sampled-token policy-gradient 版本。
- 核心贡献:
- 提出 On-Policy Self-Distillation (OPSD),不需要外部教师模型
- 利用 privileged information(如正确答案)构建 self-teacher context
- 引入 per-token pointwise divergence clipping 解决 token-level divergence 偏斜问题
- 在 MATH、GSM8K 等推理 benchmark 上验证
- 关键目标 / Loss:
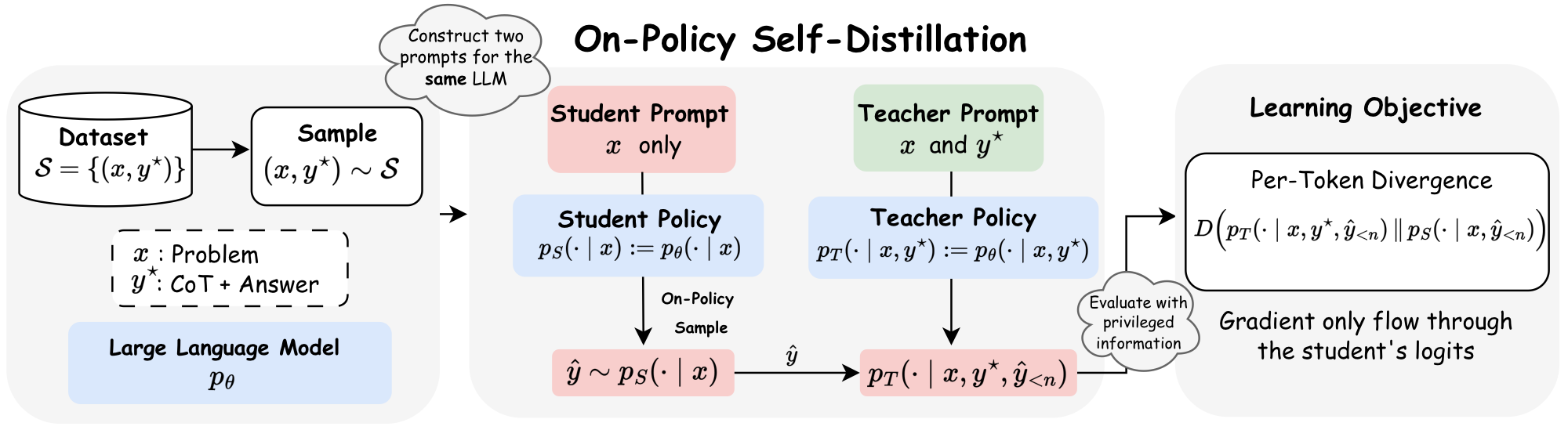
这里 teacher 和 student 是同一个模型族,但 teacher 额外看到 privileged context $y^\star$。它和普通 OPD 的区别是:teacher 不是更大的外部模型,而是“同一个模型 + 训练时额外信息”。它和 MiniLLM / Thinking Machines 的区别是:OPSD 不只给 sampled token 一个 scalar advantage,而是在同一个 student prefix 上对齐整词表分布,所以梯度支持集覆盖整个 vocabulary。
- 重要性: 扩展了 OPD 到 self-distillation 场景,无需单独的教师模型
On-Policy Context Distillation for Language Models (OPCD)
- 作者: Tianzhu Ye et al.
- 发表时间: 2026-02 (被引 7+)
- 论文: https://arxiv.org/abs/2602.12275 14
- 范式定位: GKD-style 的 context-distillation 版本。它使用 student-generated trajectories,但训练信号是在每个 prefix 上最小化 student distribution 和 context-conditioned teacher distribution 的 reverse KL,实际还可用 top-k 近似;不是 sampled-token PPO loss。
- 核心贡献:
- 将 on-policy distillation 与 context distillation 结合
- 将 in-context knowledge(few-shot examples、instructions)内化到模型参数中
- 在部署时不再需要额外的 context,降低推理成本
- 关键目标 / Loss:
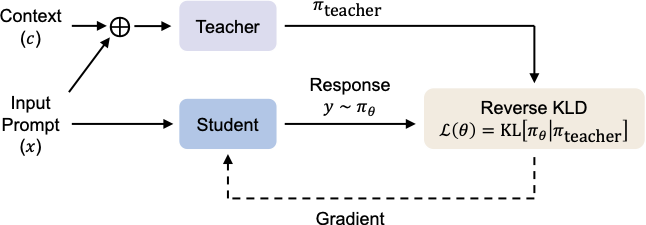
这里 $c$ 是 inference 时想省掉的额外 context。OPCD 的直觉是:student 不看 $c$ 先 rollout,teacher 看 $c$ 后在同一条 student trajectory 上给 reverse-KL 风格监督。虽然它用的是 reverse KL,但这不等于 MiniLLM-style;关键区别在于 OPCD 直接对局部 token distribution 做 KL/top-k KL,而不是把 sampled token 的 logprob ratio 写成 reward-to-go。
- 重要性: 将 OPD 范式推广到 context distillation 领域
Hindsight-Guided On-Policy Distillation
- 作者: OpenClaw-RL Team
- 发表时间: 2026-03
- 论文: https://arxiv.org/abs/2603.10165 15
- 范式定位: PG-style / sampled-token advantage。它从 next-state 中抽取 hindsight hint,构造 teacher context,然后对 agent 已经执行的 action token 计算 directional advantage;loss 直接是
sg[A_t] log pi_theta(a_t|s_t)。 - 核心贡献:
- 将 next-state 信息作为 hindsight,构建增强版教师 context
- 提供 token-level 方向优势监督
- 应用于 agent 训练场景
- 关键目标 / Loss:
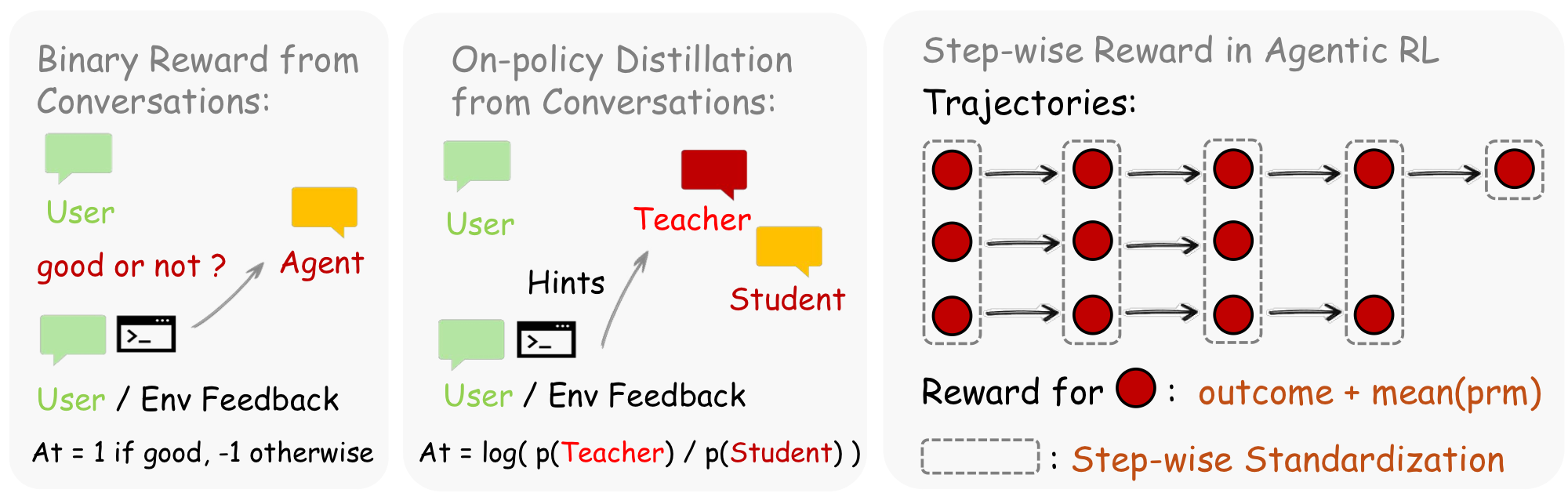
其中 $h_{t+1}$ 是从下一轮用户反馈、工具返回或环境状态变化中提炼出的 hindsight hint。它把“下一状态告诉我们刚才该怎么做”变成 token-level action supervision。它不是 full-vocab GKD-style,对 teacher 的使用更像“在已采样 action 上打分/修正方向”。
- 重要性: 这是目前最贴近“多轮交互 Agent OPD”的路线:不是只在单轮答案上做 teacher/student 对齐,而是把下一轮用户反馈、工具返回、环境状态变化变成 hindsight signal,再回头监督当前 action token。(其实也算是OPSD和OPCD的一种变体)
Reinforcement-aware Knowledge Distillation for LLM Reasoning (RLAD)
- 作者: Zhaoyang Zhang et al.
- 发表时间: 2026-02
- 论文: https://arxiv.org/abs/2602.22495 16
- 本地笔记: Reinforcement-aware Knowledge Distillation for LLM Reasoning
- 范式定位: PG-style / RL-aware hybrid。RLAD 不是额外加一个 GKD-style KL loss,而是把 teacher-student ratio 写进 PPO/GRPO-style likelihood ratio,让 teacher 影响 trust region 和更新幅度,方向仍由 RL advantage 锚定。
- 核心贡献:
- 提出 RL-Aware Distillation (RLAD),在 RL post-training 过程中做 selective imitation。
- 提出 Trust Region Ratio Distillation (TRRD),把 teacher policy 变成 PPO/GRPO 更新里的 mixture anchor,而不是独立 teacher KL regularizer。
- 解决
KDRL式 teacher-KL 和 reward maximization 互相干扰的问题:teacher 主要调节 trust region 的宽窄,reward advantage 仍然决定更新方向。
- 关键目标 / Loss:
RLAD 的核心是 TRRD ratio,把 teacher policy 放进 PPO/GRPO 的 ratio 里:
也可以理解成:
\[r^{\mathrm{TRRD}}_{i,t} = \frac{\pi_{\theta^S}(y_t^{(i)}|s_t)} {(\pi_{\theta^{S,\mathrm{old}}})^\alpha(\pi_{\theta^T})^{1-\alpha}}.\]然后把 GRPO objective 里的 $r^{\mathrm{GRPO}}$ 替换成 $r^{\mathrm{TRRD}}$:
\[J_{\mathrm{RLAD}} = \mathbb{E} \sum_{i,t} \min\!\left( r^{\mathrm{TRRD}}_{i,t}\hat A_{i,t}, \mathrm{clip}(r^{\mathrm{TRRD}}_{i,t},1-\epsilon,1+\epsilon)\hat A_{i,t} \right) - \beta D_{\mathrm{KL}}(\pi_{\theta^S}\|\pi_{\mathrm{ref}}).\]这里 $\alpha$ 控制 teacher anchor 和 old-student anchor 的比例。按公式和附录解释,$\alpha=1$ 退化成标准 GRPO,$\alpha\rightarrow 0$ 则更接近 teacher-anchored / DPO-like reference optimization。正文里有一句关于端点的描述疑似写反,读公式时最好以这个解释为准。
这和普通 KL distillation 的核心区别是:teacher 影响更新幅度和 trust region,但 reward advantage 仍决定更新方向。 因此它更接近 MiniLLM/PG-style 的“sampled action 上调 policy ratio”,只是 reward/advantage 来自 RL 任务而不是纯 teacher-student reverse-KL。
- 实验结论:
- 逻辑推理
K&K Logistics上,Qwen3-0.6B8K context 的 Avg 从GRPO的0.76提到RLAD的0.94,2K context 从0.70提到0.90。 - 长上下文数学上,
Qwen3-8B-Base+Qwen3-32Bteacher 的 Avg 从GRPO的61.0提到RLAD的66.5。 - 收益主要集中在
PPL7/PPL8、AIME24/25这类更难场景;简单 benchmark 上提升较小,说明 teacher-aware trust region 最有价值的是能力边界附近的 rollout。
- 逻辑推理
- 重要性: 把 OPD 信号嵌入 RL 训练本身,而不是在 RL 外面再加一个蒸馏 loss;这让 teacher 主要承担“调节更新幅度 / trust region”的角色,更适合 reasoning RL 场景。
Self-Distilled RLVR
- 作者: arXiv 2026
- 发表时间: 2026-04-03
- 论文: https://arxiv.org/abs/2604.03128 17
- 范式定位: PG-style / GRPO-style reweighting。RLSD 不让 teacher 分布直接定义更新方向,也不做 full-vocab distillation;它只用 self-distillation 的 token-level logprob gap 调节 RLVR/GRPO 的 token credit magnitude。
- 核心贡献:
- 提出 RLSD (Self-Distilled RLVR),指出 OPSD 的问题不是实现细节,而是 privileged teacher 决定 gradient direction 会造成结构性泄漏。
- 将 self-distillation 信号从“决定更新方向的 teacher target”改成“只调节 token-level credit magnitude”的 reweighting 信号。
- 保留 RLVR / GRPO 的环境 reward 方向锚定,同时用 privileged teacher 的 logprob ratio 细化每个 token 的 credit assignment。
- 关键目标 / Loss:
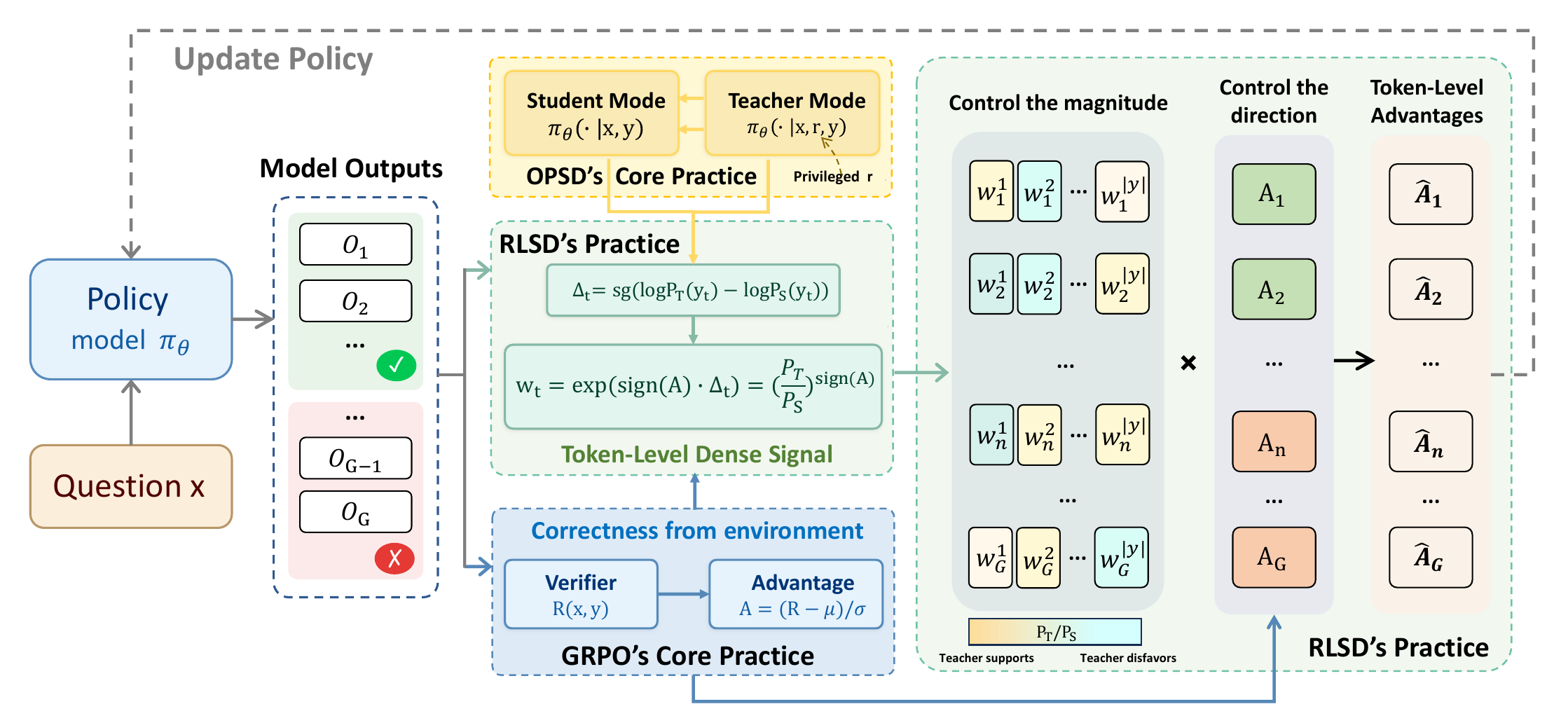
先计算 privileged information gain:
\[\Delta_t = \mathrm{sg} \left[ \log P_T(y_t) - \log P_S(y_t) \right].\]再用环境 advantage 的符号决定 teacher 信号如何进入 token weight:
\[w_t = \exp\!\left(\mathrm{sign}(A)\Delta_t\right) = \left( \frac{P_T(y_t)}{P_S(y_t)} \right)^{\mathrm{sign}(A)}.\]最终把 sequence-level advantage 重分配成 token-level advantage:
\[\hat A_t = A\cdot \mathrm{clip} \left( w_t,\, 1-\epsilon_w,\, 1+\epsilon_w \right).\]所以 RLSD 和 OPSD 的关键差别是:OPSD 让 privileged teacher 决定更新方向,RLSD 只让 teacher 决定同一条轨迹内部哪些 token 更该分到 credit / blame。从 GKD/PG 二分看,RLSD 明显不是 GKD-style,因为 teacher 不给全词表 target;它是在 GRPO 的 sampled trajectory 上重分配 token-level advantage。
- 重要性: 这是对 self-distillation OPD 的一次重要纠偏:它说明“dense token signal”不一定安全,关键是 teacher signal 进入 loss 的位置。
RLAD 和 RLSD 的区别
两者哲学上很像:都反对 teacher / distillation signal 直接决定“奖还是罚”,而是让 environment reward / advantage 锚定更新方向。但它们把 teacher 信号放进 loss 的位置不同,所以不是把 $\alpha$ 换成 $\lambda$ 这么简单。
| 维度 | RLAD / TRRD | Self-Distilled RLVR / RLSD |
|---|---|---|
| teacher 来源 | 外部更强 teacher,例如 Qwen3-8B/32B | 同一个模型加 privileged information / final answer,自蒸馏 |
| 解决的问题 | KDRL 这类 teacher-KL 和 RL objective 打架 | OPSD 让 privileged teacher 决定方向,导致 leakage / 后期崩 |
| teacher 信号放哪 | 放进 policy ratio 的 denominator / trust region anchor | 放进 token-level advantage 的 magnitude / credit weight |
| 核心公式 | $r^{\mathrm{TRRD}}=\frac{\pi_S}{\pi_{\mathrm{old}}^\alpha\pi_T^{1-\alpha}}$ | $\hat A_t=A\cdot((1-\lambda)+\lambda\cdot \mathrm{clip}(w_t))$ |
| teacher 能做什么 | 改变 PPO/GRPO clipping 边界,放宽或收紧 policy update | 重新分配 token credit / blame,但不改变正负号 |
| 退化回 GRPO | $\alpha=1$ | $\lambda=0$ |
可以把二者的差别压成一句话:RLAD 是 teacher-aware trust-region shaping,RLSD 是 teacher-aware token credit assignment。 前者调“policy 可以往某个方向走多远”,后者调“同一条轨迹里哪些 token 多背锅 / 多领奖”。
Black-Box On-Policy Distillation of Large Language Models (GAD)
- 作者: Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, Furu Wei
- 发表时间: 2025-11
- 论文: https://arxiv.org/abs/2511.10643 18
- 代码: https://github.com/microsoft/LMOps/tree/main/gad
- 项目页: https://ytianzhu.github.io/Generative-Adversarial-Distillation/
- 本地笔记: GAD
- 范式定位: black-box / PG-style OPD。GAD 面向
GPT-5-Chat这类 API-only teacher,拿不到 logits、hidden states 或 teacher probability,只能拿到 teacher response 文本。因此它不是 GKD-style full-vocab distillation,而是训练一个 sequence-level discriminator 作为在线 reward model,再用GRPO在 student 自己 rollout 上优化。 - 核心贡献:
- 提出 Generative Adversarial Distillation (GAD),把 student 看成 generator,把 discriminator 看成随 student 一起演化的 reward model。
- 将 black-box teacher 只能给文本的问题,转化成 teacher response vs current student response 的 pairwise preference learning。
- warmup 后不再只做
SeqKDteacher forcing,而是在 student on-policy samples 上由 discriminator 给 reward,从而补上 black-box distillation 缺失的 on-policy feedback。
- 关键目标 / Loss:
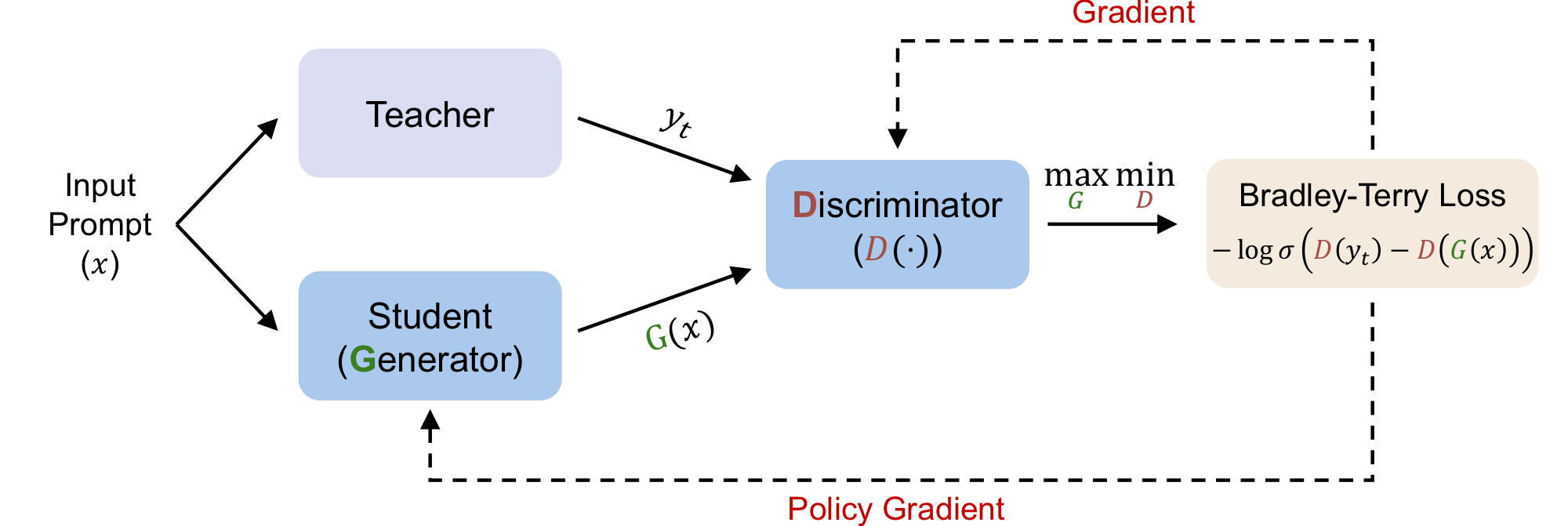
给定 prompt $x$ 和 black-box teacher response $y_t$,student / generator 生成 $G(x)$。Discriminator $D([x,y])$ 输出一个 sequence-level scalar score。GAD 的 minimax game 可以写成:
\[\max_G \min_D\ \mathcal{V}(G,D) = \mathbb{E}_{(x,y_t)\sim\mathcal{T}} \left[ -\log \sigma\left(D(y_t)-D(G(x))\right) \right].\]拆开看,discriminator 用 Bradley-Terry loss 学会给 teacher response 更高分:
\[\min_D \mathbb{E}_{(x,y_t)\sim\mathcal{T}} \left[ -\log \sigma\left(D(y_t)-D(G(x))\right) \right],\]student 则最大化自己 response 的 discriminator score:
\[\max_G\ \mathbb{E}_{(x,y_t)\sim\mathcal{T}} \left[D(G(x))\right].\]实际 student 更新仍然用 GRPO。对每个 prompt 采样一组 student responses ${y_s^i}_{i=1}^N$,用 discriminator score 当 reward:
所以 GAD 的创新不在于替换 GRPO,而在于 black-box teacher 场景下如何构造一个跟随 student policy 分布更新的 reward signal。这点和 SeqKD 的区别很大:SeqKD 只在 teacher response 上做 CE,而 GAD 在 student 自己生成的 response 上学习“像不像 teacher / 是否更高质量”。
- 实验结论:
- 在
Qwen2.5-14B-Instruct <- GPT-5-Chat设置下,GAD在LMSYS自动评测上达到52.1,高于SeqKD的50.6,也接近或略高于论文报告的 teacherGPT-5-Chat的51.7。 - OOD 平均分上,
Qwen2.5-14B-Instruct + GAD达到51.03,高于SeqKD的49.10。 - Human evaluation 中,
Qwen2.5-14B-Instruct + GAD相比SeqKD的胜率为68%,败率为24%。
- 在
- 重要性: GAD 把 OPD 的 on-policy 思想推到 black-box teacher 场景:即使没有 teacher logits,只要有 teacher 文本,也可以通过在线 discriminator 给 student rollout 构造 dense-ish sequence-level feedback。它更像是“black-box OPD 的 reward construction 方法”,而不是普通的 logits 蒸馏 loss。
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
- 作者: Yaxuan Li et al.
- 发表时间: 2026-04 / arXiv 2026
- 论文: https://arxiv.org/abs/2604.13016 19
- 代码: https://github.com/thunlp/OPD
- 本地笔记: Rethinking OPD
- 范式定位: mechanism / recipe paper。这篇不是提出一个新的
OPD loss,而是把 OPD 当成一个需要拆开的训练动力学对象:什么时候 OPD 会成功,为什么它会成功,失败时怎么救,以及 dense token reward 的边界在哪里。 - 核心贡献:
- 指出 OPD 成败的两个更具体的条件:
teacher/student是否有相容的 thinking pattern- teacher 是否真的提供了 student 训练中没学过的新能力,同族模型更大尺寸benchmark分数更高,对student不一定有效果
- 提出一组很实用的 token-level 诊断指标,包括
overlap ratio、overlap-token advantage和entropy gap,用来判断 teacher 信号是否能在 student 已访问状态上被利用。- overlap ratio 即使不断上涨,测评及分数也不一定好
- 机制上指出,成功的 OPD 主要发生在双方高概率共享 token 区域里;这个共享区域虽然只是一小块 top-
ktoken,但往往承载97%到99%的概率质量。 - 给出两类实践的 recipe:
- 先用 teacher rollouts 做
off-policy cold start - 让 OPD 使用更接近 teacher post-training 分布的 prompt template / prompt content。
- 先用 teacher rollouts 做
- 讨论 OPD dense reward 的边界:
- trajectory 越长,teacher 在 student 偏移 prefix 上给出的 token-level reward 越容易变噪;
- 全局有信息的 reward 也未必能形成局部可优化的梯度方向。
- 指出 OPD 成败的两个更具体的条件:
2.3 Technical Report 里的 OPD
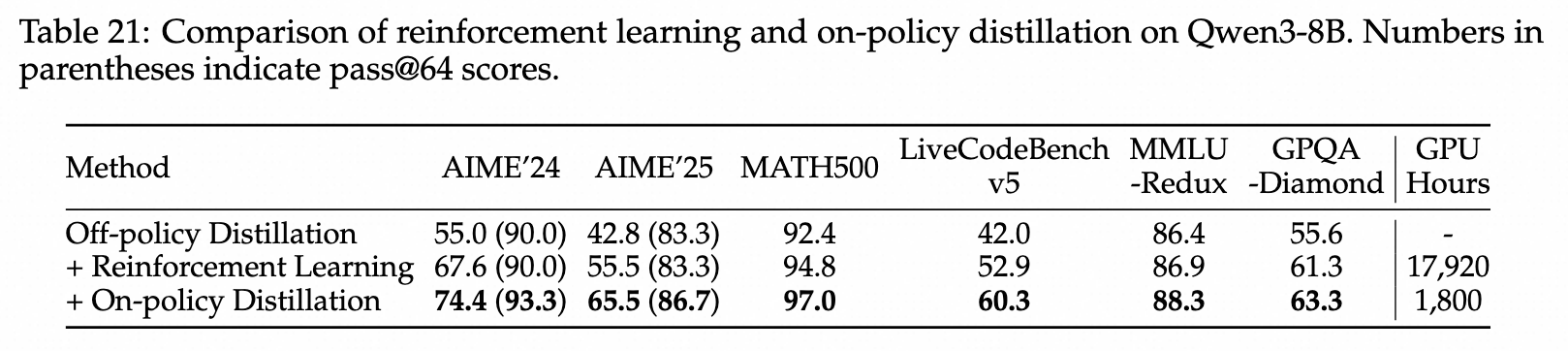
Qwen3 —Strong-to-Weak Distillation
- 团队: Qwen Team (Alibaba)
- 发布时间: 2025-05 (被引 9200+)
- 论文: https://arxiv.org/abs/2505.09388
- 核心贡献:
- 在 Qwen3 系列轻量模型训练中大规模使用 on-policy distillation
- 训练流程:Cold-start SFT → Reasoning RL → On-Policy Distillation(最后一步)
- 学生模型生成 on-policy 序列,与教师(Qwen3-32B / Qwen3-235B)的 logits 对齐
- 证明 OPD 在小模型上可以以远低于 RL 的计算成本获得相当的推理性能
- 关键目标 / Loss:
技术报告没有展开完整训练公式,但核心就是:小模型先用当前 policy 采样,再在这些 student-visited prefixes 上对齐强 teacher logits。
- 重要性: 首次在工业级大规模模型训练中验证 OPD 的有效性

- 相比RL,OPD效果更好,且更节省资源(只在code和math任务上验证了)
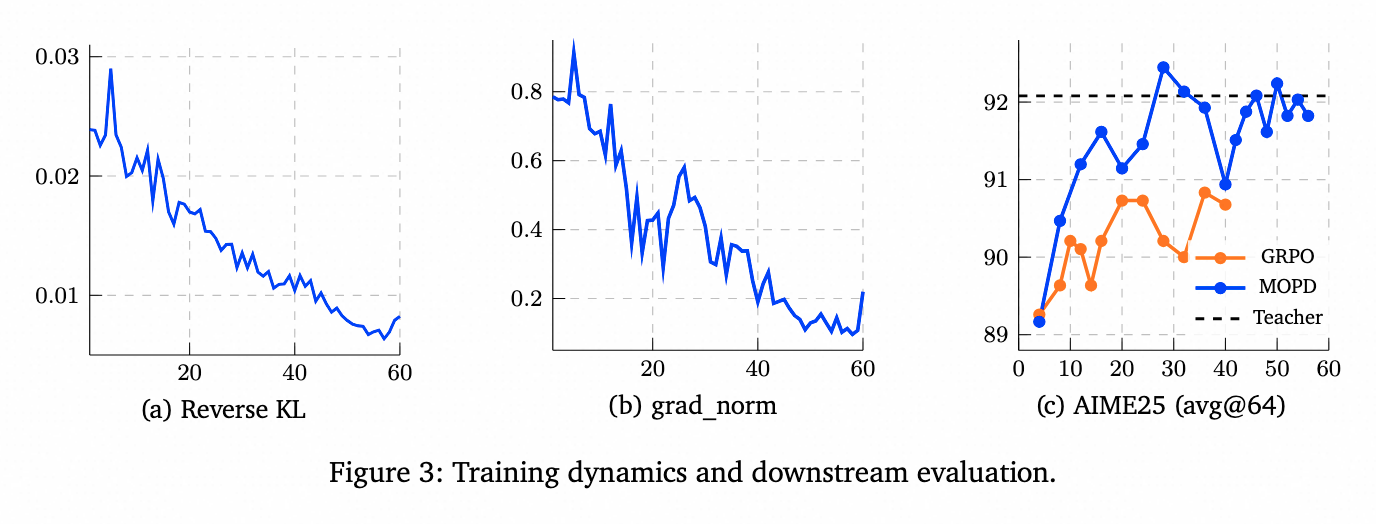
MiMo-V2-Flash — Multi-Teacher On-Policy Distillation (MOPD)
- 作者: Xiaomi LLM-Core Team
- 发表时间: 2026-01
- 论文: https://arxiv.org/abs/2601.02780
- 代码/模型: https://github.com/XiaomiMiMo/MiMo-V2-Flash
- 核心贡献:
- 提出 Multi-Teacher On-Policy Distillation (MOPD),把多领域专家 teacher 的能力回灌到统一 student。
- Student 在自己的 rollout 分布上采样,领域 teacher 在每个 token 上提供 dense guidance,而不是只给 sequence-level reward。
- 训练信号可理解为 teacher/student token logprob ratio 诱导出的 reverse-KL advantage,并可叠加 ORM 的 outcome advantage。
- 方法被用于 reasoning、code、search、general agent 等能力整合,并在 SWE-Bench、Tau2-Bench、tool-use 等 agent 指标上验证。
- 关键目标 / Loss:
默认还可叠加 outcome reward model 的优势:
\[\hat A_{\mathrm{final},t} = \hat A_{\mathrm{MOPD},t} + \alpha \hat A_{\mathrm{ORM}}.\]这里 $\mu_\theta$ 是 inference engine 的 rollout policy,$\pi_\theta$ 是 training engine 的 policy,所以需要 truncated importance sampling。 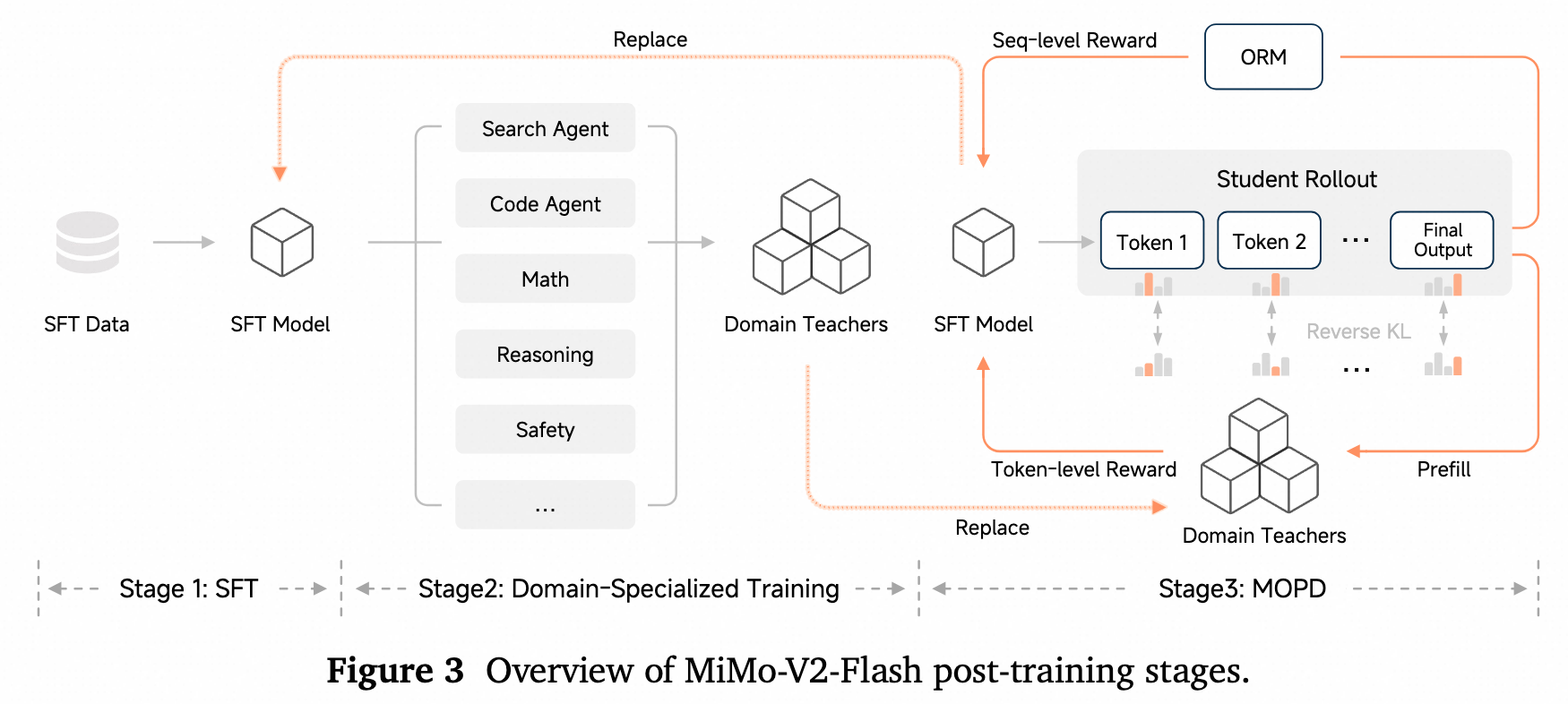
- 实验结果表明,MOPD比直接用ORM效果更好
- MOPD with ORM在livecodebench上,比without ORM效果好(with ORM效果不是一致的更好)
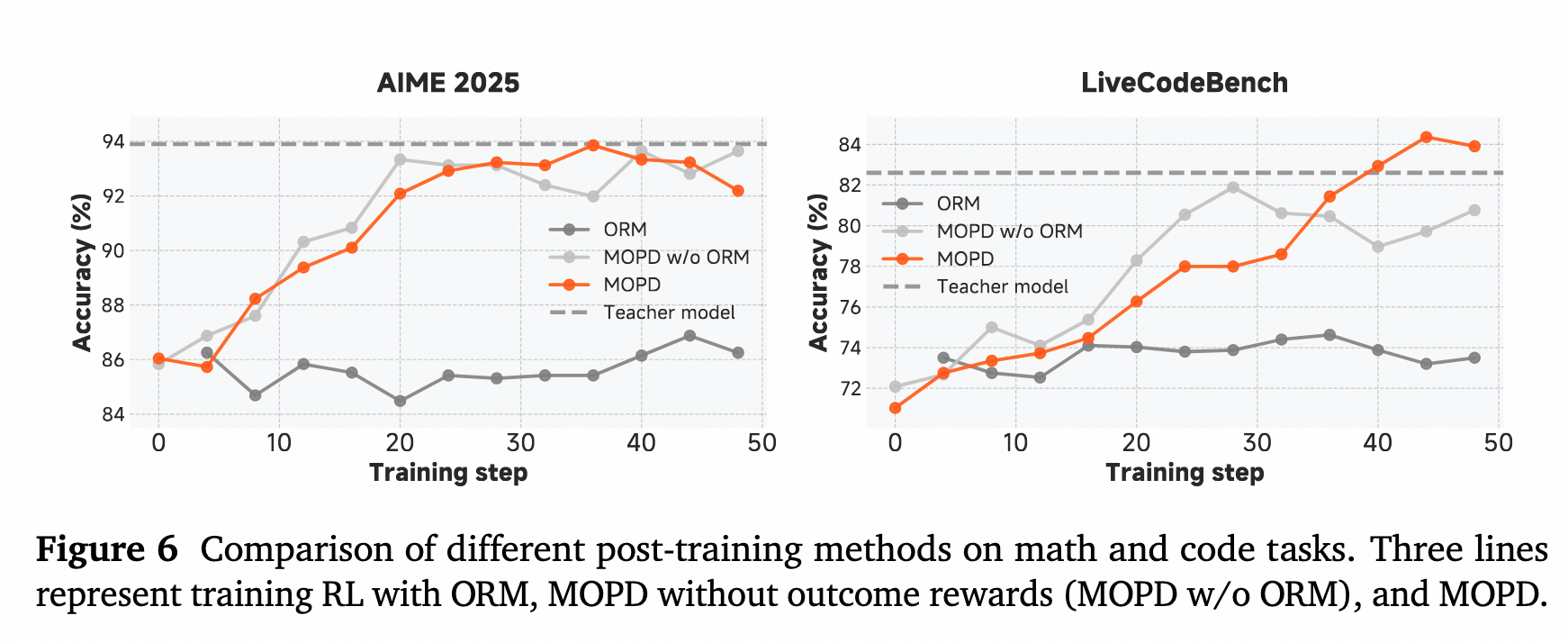 总结: MiMo-V2-Flash 把 OPD 从“小模型模仿大 teacher”的经典蒸馏,推进到“多个 RL 专家 teacher 合并成一个 agent foundation model”的工业 recipe。
总结: MiMo-V2-Flash 把 OPD 从“小模型模仿大 teacher”的经典蒸馏,推进到“多个 RL 专家 teacher 合并成一个 agent foundation model”的工业 recipe。
GLM-5 — On-Policy Cross-Stage Distillation
- 作者: Z.ai / GLM Team
- 发表时间: 2026-02
- 论文: https://arxiv.org/abs/2602.15763 20
- 代码/模型: https://github.com/zai-org/GLM-5
- 核心贡献:
- 在
GLM-5的 post-training pipeline 里,把SFT -> Reasoning RL -> Agentic RL -> General RL之后的最后一步设计成 On-Policy Cross-Stage Distillation。 - 目的不是单纯“小模型模仿大 teacher”,而是把前面多个 RL 阶段的最终 checkpoint 当作 teacher,回收 reasoning / agentic / general RL 阶段已经学到的能力。
- 解决顺序式多阶段 RL 的一个现实问题:模型在学新能力时可能遗忘旧能力,所以最后需要一轮 on-policy distillation 做 capability consolidation / anti-forgetting。
- 在
- 关键目标 / Loss:
原文 3.5节 明确说 cross-stage distillation 的训练目标不是单独新写一个 KL loss,而是沿用前面 Reasoning RL 的公式 (1),即带 IcePop 修正的 clipped RL objective:
\[\begin{aligned} \mathcal{L}(\theta) = -\mathbb{E}_{ x \sim \mathcal{D}, \{y_i\}_{i=1}^{G} \sim \pi_{\theta_{\mathrm{old}}}^{\mathrm{infer}}(\cdot\mid x) } &\Bigg[ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \operatorname{pop}(\rho_{i,t},1/\beta,\beta) \\ &\cdot \min\left( r_{i,t}\hat A_{i,t}, \operatorname{clip} \left( r_{i,t}, 1-\epsilon_{\mathrm{low}}, 1+\epsilon_{\mathrm{high}} \right) \hat A_{i,t} \right) \Bigg]. \end{aligned}\]其中 $\rho_{i,t}$ 是 training / inference engine 之间的 mismatch ratio,$\operatorname{pop}(\cdot)$ 用来过滤偏离过大的 token,$r_{i,t}$ 是 PPO/GRPO 风格的 importance ratio。到了 On-Policy Cross-Stage Distillation,原文说把公式 (1) 里的 advantage 项替换为:
\[\hat A_{i,t} = \mathrm{sg} \left[ \log \frac{ \pi_{\theta_{\mathrm{teacher}}}^{\mathrm{infer}}(y_{i,t}\mid x,y_{i,<t}) }{ \pi_{\theta}^{\mathrm{train}}(y_{i,t}\mid x,y_{i,<t}) } \right].\]也就是说,外层仍然是同一个 on-policy RL / IcePop 框架,变的是 $\hat A_{i,t}$ 的来源:它不再来自 reward 组内归一化,而是来自 teacher inference policy 与 student training policy 在采样 token 上的 logprob gap。 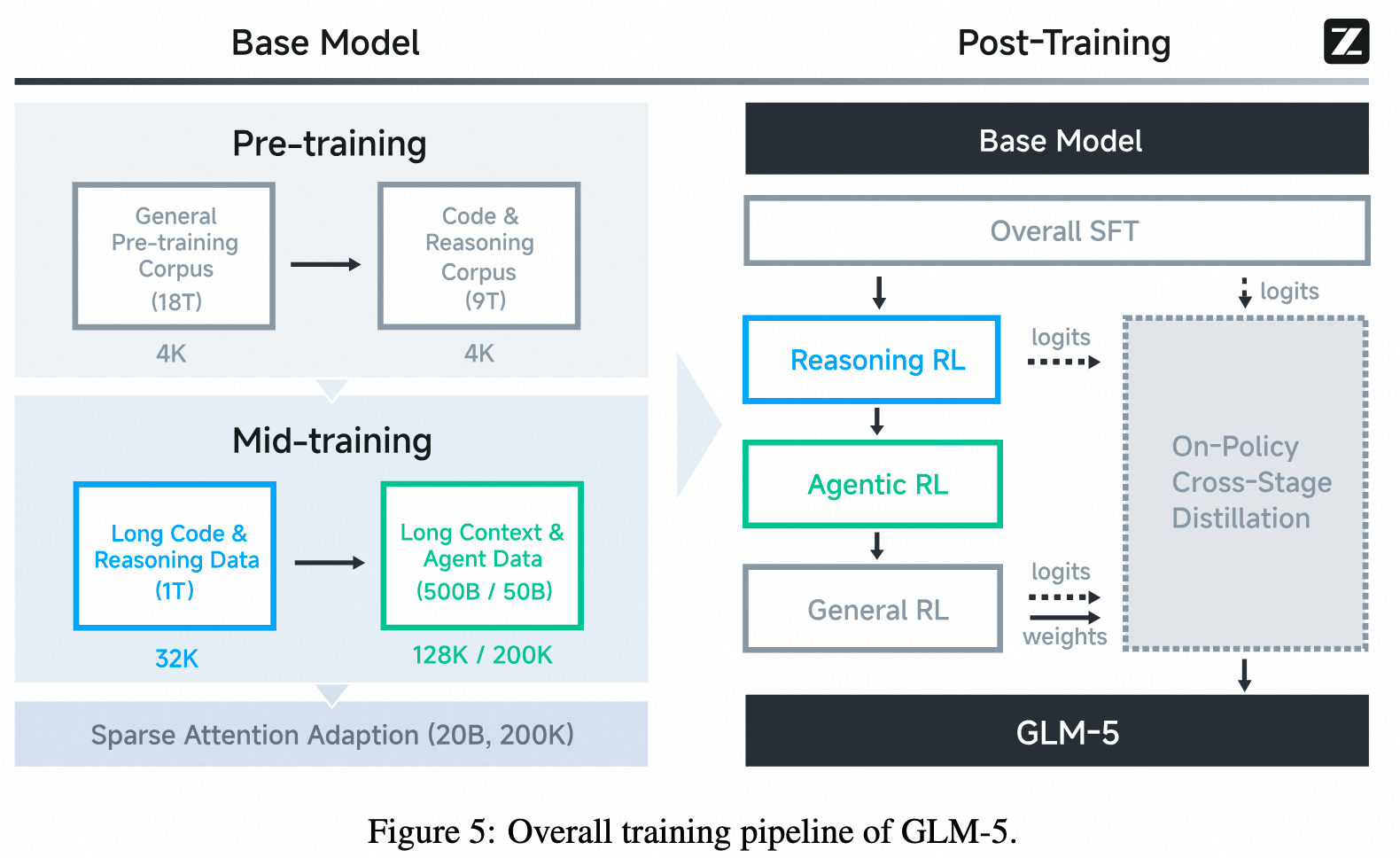
- 没有给OPD相关的实验分析
- 重要性: GLM-5 把 OPD 放进 agentic engineering 的大规模系统训练流程里,作为多阶段 RL 的最后一个能力整合的阶段;这说明 OPD 在 technical report 语境下正在从“蒸小模型”扩展成“长期多阶段训练里的 anti-forgetting / capability consolidation 机制”。
Nemotron-Cascade 2 — Multi-Domain On-Policy Distillation
- 作者: NVIDIA Nemotron Team
- 发表时间: 2026-03
- 论文/项目: https://research.nvidia.com/labs/nemotron/nemotron-cascade-2/
- 核心贡献:
- 在 Cascade RL 流程中加入 Multi-Domain On-Policy Distillation,把 OPD 作为多阶段 RL 的中间恢复机制。
- 对每个领域选取 Cascade RL 过程中表现最强的 intermediate teacher,再把这些 domain teacher 的能力蒸馏回统一模型。
- 目标不是只追求单一领域峰值,而是在继续训练更复杂 RL 环境时,恢复 benchmark regression 并保留之前领域的性能。
- 覆盖数学、代码、instruction following、agentic tool calling、structured output 等多类能力,并公开模型 checkpoint 和训练数据集合。
- 关键目标 / Loss:
Nemotron-Cascade 2 和 GLM-5 的形式很像,都是PG-Style的. 训练时,MOPD作为一个中间阶段,后续还进行了额外的RL训练阶段。 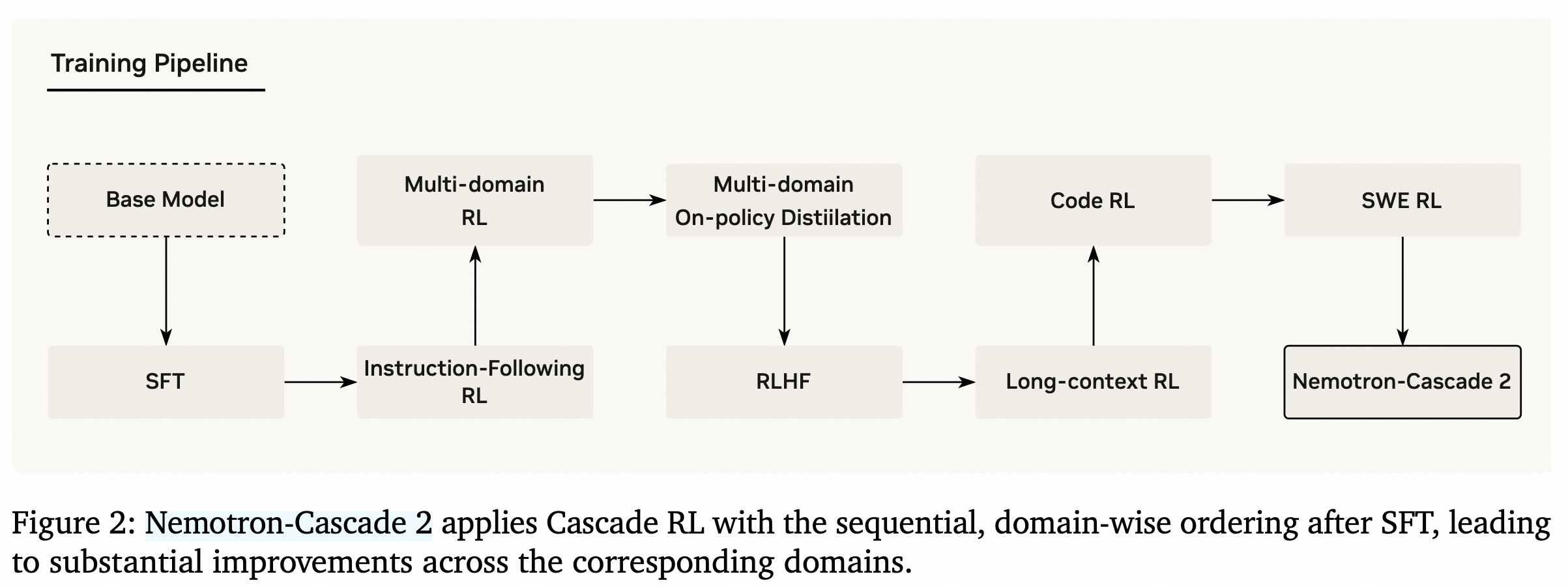
- 实验结果表明,在AIME25上能比GRPO高一个点左右
DeepSeek-V4 — Full-Vocabulary Multi-Teacher OPD at Scale
- 作者: DeepSeek-AI Team
- 发表时间: 2026-04(preview technical report)
- 论文: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
- 核心贡献:
- 在
DeepSeek-V4的 post-training pipeline 里,用 OPD 完整替换了DeepSeek-V3.2中的 mixed RL 阶段。 - 先训练多个 domain specialist:每个专家仍然走
SFT + GRPO,对 hard-to-verify 任务还引入GRM;然后再用 multi-teacher OPD 把这些专家统一蒸馏回单一模型。 - 明确批评 prior work 常见的 sampled-token KL / RL-style advantage 近似方差太高,转而采用 full-vocabulary logit distillation 来直接计算 reverse KL。
- 技术报告最有价值的部分不只是公式,而是把 teacher scheduling、teacher offloading、hidden-state caching、exact KL kernel 这套工程路径写清楚,说明 full-vocab OPD 不是只能停留在小规模研究原型。
- 在
- 关键目标 / Loss:
这里 $\pi_\theta$ 是 unified student policy,$\pi_{E_i}$ 是第 $i$ 个 domain expert teacher,$w_i$ 是不同 teacher 的权重。(论文提到, DeepSeek-V4 的专家数超过10个)
报告还特别强调:很多已有实现会把 full-vocab KL 退化成 sampled-token 的 per-token 近似,例如在 student 采样 token 上构造
\[\log \pi_{E_i}(y_t|s_t)-\log \pi_\theta(y_t|s_t)\]这类 advantage 再塞进 RL-style loss。DeepSeek-V4 的判断是:这种做法虽然省算力,但梯度方差更高,也更容易训练不稳定;因此他们在OPD 阶段宁可付出更高工程成本,也要保留完整词表分布来计算 reverse KL。(但论文没有说明是用的GKD-Style还是PG-Style的方式更新)
有10几个Teacher来做OPD,每个Teacher都是万亿级(超过1T)的参数量,所以做了很多工程优化:
- teacher 权重统一 offload 到中心化分布式存储,需要时再以 ZeRO-like shard 方式加载,支持
10+个 teacher 的 multi-teacher OPD。 - 不缓存 full logits,而是只缓存 teacher 最后一层 hidden states;训练时再过各自 prediction head,在线重建 full logits。
- mini-batch 按 teacher index 排序,同一时刻最多只保留一个 teacher head 在显存中,降低 full-vocab distillation 的显存峰值。
- 所有参数与 hidden state 的加载/卸载异步执行,exact KL 由专门的
TileLangkernel 计算。 - rollout、teacher forward 和 reference forward 还结合了
FP4推理路径,进一步压缩 full-vocab OPD 的代价。
总结:
- 与Mimo-V2,GLM-5的区别,是用了full-vocab的kl计算
- 论文没有清楚写出是用GKD-Syle的更新还是PG-Style的更新
- 没有给OPD相关的实验分析
3. 开源实现
3.1 HuggingFace TRL — GKDTrainer & GOLD
| 项目 | 详情 |
|---|---|
| 仓库 | https://github.com/huggingface/trl |
| 文档 | https://huggingface.co/docs/trl/gkd_trainer |
| Stars | 12k+ |
| 框架 | PyTorch + Transformers |
支持的方法:
- GKD (Generalized Knowledge Distillation): 完整实现了 Agarwal et al. 的方法
- GOLD (General On-Policy Logit Distillation): 支持跨模型家族蒸馏
特点:
- 与 HuggingFace 生态深度集成 (Transformers, Datasets, Accelerate)
- 支持 on-policy / off-policy / mixed 数据生成策略
- 支持 forward KL / reverse KL / JSD 等多种散度
- 支持 PEFT/LoRA 训练
- 文档完善,社区活跃
使用示例:
from trl import GKDConfig, GKDTrainer
training_args = GKDConfig(
output_dir="./gkd_output",
per_device_train_batch_size=4,
max_new_tokens=128,
temperature=0.9,
lmbda=0.5, # on-policy 与 off-policy 数据混合比例
)
trainer = GKDTrainer(
model=student_model,
teacher_model=teacher_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()
推荐度: ⭐⭐⭐⭐⭐ (最成熟、最易用的开源实现)
3.2 Microsoft LMOps — MiniLLM
| 项目 | 详情 |
|---|---|
| 仓库 | https://github.com/microsoft/LMOps/tree/main/minillm |
| Stars | 4k+ (LMOps 总仓库) |
| 框架 | PyTorch + Transformers |
特点:
- MiniLLM 论文的官方实现
- 基于 policy gradient 优化 reverse KL
- 支持 GPT-2、OPT、LLaMA 等模型
- 提供完整的训练脚本和评测代码
- 已被集成到 HuggingFace TRL 中
推荐度: ⭐⭐⭐⭐ (学术参考价值高,已有 TRL 集成版本)
3.3 NVIDIA NeMo-RL — On-Policy Distillation
| 项目 | 详情 |
|---|---|
| 仓库 | https://github.com/NVIDIA-NeMo/RL |
| 文档 | https://docs.nvidia.com/nemo/rl/latest/about/algorithms/on-policy-distillation.html |
| 框架 | PyTorch + NeMo |
特点:
- 原生支持大规模分布式训练 (multi-node, multi-GPU)
- 支持 DTensor 和 vLLM generation backend
- 提供 DeepScaler 数据集上的示例实验
- 使用 Ray 进行分布式调度
- 默认使用 Qwen3 模型(Qwen3-1.7B-Base → Qwen3-4B)
使用示例:
# 单节点
uv run python examples/run_distillation_math.py \
policy.model_name="Qwen/Qwen3-1.7B-Base" \
teacher.model_name="Qwen/Qwen3-4B" \
cluster.gpus_per_node=8
# 多节点 (Slurm)
sbatch --nodes=2 --gres=gpu:8 ray.sub
推荐度: ⭐⭐⭐⭐⭐ (生产级分布式 OPD 首选)
3.4 verl — On-Policy Distillation / Async KD
| 项目 | 详情 |
|---|---|
| 仓库 | https://github.com/verl-project/verl |
| 文档 | https://verl.readthedocs.io/en/latest/advance/async-on-policy-distill.html |
| 示例 | https://github.com/verl-project/verl/tree/main/examples/on_policy_distillation_trainer |
| 最新版本 | v0.7.1 (2026-03-16);main 分支已到 0.8.0.dev |
| Stars | 20k+ |
| 框架 | PyTorch + Ray + FSDP/Megatron + vLLM/SGLang |
支持的方法:
- On-Policy Knowledge Distillation: 学生模型先生成 on-policy rollout,教师模型再返回 top-k token log-probs / token indices
- Token-level sparse KL distillation: 在教师 top-k 支持集上计算逐 token KL,提供 dense supervision
- Async On-Policy KD: 支持
one_step_off/two_step_off调度,把 rollout generation、teacher querying、actor update 重叠起来 - 示例中暴露
forward_kl_topk、k1、k3等 distillation loss mode,并可选择是否结合 policy gradient / task rewards
特点:
- verl 是 ByteDance Seed 发起的生产级 RLHF / post-training 框架,已迁移到
verl-project/verl维护 - OPD 已成为一等训练配方,而不是外部 hack;主线示例可通过
distillation.enabled=True在 PPO/GRPO 训练入口中开启 - 同时提供 FSDP 路线、Megatron 路线和 Qwen3-VL/Geo3K 多模态示例,适合从文本推理扩展到 VLM 蒸馏
- 教师侧可用 vLLM/SGLang 推理服务提供 top-k 分布,学生侧可用 Ray 调度独立 actor / rollout / teacher 资源池
- 相比 TRL,上手成本更高(Ray、资源划分、teacher serving、weight sync 都要配置),但可扩展性和系统吞吐优化更强
使用示例:
# FSDP 文本蒸馏示例
bash examples/on_policy_distillation_trainer/run_qwen_gsm8k.sh
# Megatron 文本蒸馏示例
bash examples/on_policy_distillation_trainer/run_qwen_gsmk8_megatron.sh
# 多模态蒸馏示例
bash examples/on_policy_distillation_trainer/run_qwen3_vl_geo3k.sh
推荐度: ⭐⭐⭐⭐⭐ (大规模 RL/OPD 统一训练框架;工程门槛高,但系统能力很强)
3.5 Arcee AI — DistillKit
| 项目 | 详情 |
|---|---|
| 仓库 | https://github.com/arcee-ai/DistillKit |
| 框架 | PyTorch + Transformers |
特点:
- 专注于模型蒸馏的轻量级工具库
- 支持 logit distillation 和 hidden states distillation
- 提供 on-policy 数据生成管线
- 简洁的 API 设计,易于上手
推荐度: ⭐⭐⭐ (轻量级选择)
3.6 Thinking Machines — Tinker (On-Policy Distillation Blog)
| 项目 | 详情 |
|---|---|
| 博客 | https://thinkingmachines.ai/blog/on-policy-distillation/ |
| 框架 | 基于 Tinker training API |
特点:
- 详尽的技术博客,从原理到实现完整讲解
- 使用 reverse KL 损失函数
- 复现了 Qwen3 的 OPD 结果
- 提供 Tinker cookbook 可供跟随实践
推荐度: ⭐⭐⭐⭐ (学习资源价值极高)
3.7 其他相关开源项目
| 项目 | 链接 | 说明 |
|---|---|---|
| OpenRLHF | https://github.com/openrlhf/openrlhf | 可扩展的 RLHF 框架,支持在 RL 流程中集成蒸馏 |
| THUDM/slime | https://github.com/THUDM/slime | 支持 on-policy distillation 的训练框架 |
| ms-swift | https://github.com/modelscope/ms-swift | ModelScope 训练框架,文档中有 OPD 支持 |
| Awesome-KD-of-LLMs | https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs | 论文集合,持续更新 |
参考文献
-
Geoffrey Hinton, Oriol Vinyals, Jeff Dean, Distilling the Knowledge in a Neural Network, 2015. arXiv: https://arxiv.org/abs/1503.02531 ↩ ↩2
-
A Survey of On-Policy Distillation for Large Language Models, 2026. arXiv: https://arxiv.org/abs/2604.00626 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
Yoon Kim, Alexander M. Rush, Sequence-Level Knowledge Distillation, 2016. arXiv: https://arxiv.org/abs/1606.07947 ↩
-
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, Dawn Song, The False Promise of Imitating Proprietary LLMs, 2023. arXiv: https://arxiv.org/abs/2305.15717 ↩
-
Stéphane Ross, Geoffrey J. Gordon, J. Andrew Bagnell, A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning, AISTATS 2011. PMLR: https://proceedings.mlr.press/v15/ross11a.html ↩ ↩2
-
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, Olivier Bachem, On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, ICLR 2024. arXiv: https://arxiv.org/abs/2306.13649 ↩ ↩2 ↩3 ↩4
-
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang, MiniLLM: On-Policy Distillation of Large Language Models, ICLR 2024. arXiv: https://arxiv.org/abs/2306.08543 ↩ ↩2 ↩3
-
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, Ngai Wong, Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models, COLING 2025. arXiv: https://arxiv.org/abs/2404.02657 ↩
-
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, PACED: Distillation and Self-Distillation at the Frontier of Student Competence, 2026. arXiv: https://arxiv.org/abs/2603.11178 ↩
-
Jianhua Lin, Divergence Measures Based on the Shannon Entropy, IEEE Transactions on Information Theory, 1991. DOI: https://doi.org/10.1109/18.61115 ↩
-
Thinking Machines Lab, On-Policy Distillation, 2025. Blog: https://thinkingmachines.ai/blog/on-policy-distillation/ ↩
-
Hugging Face H4 Team, GOLD: Unlocking On-Policy Distillation for Any Model Family, 2025. Project page: https://huggingface.co/spaces/HuggingFaceH4/on-policy-distillation ↩
-
Siyan Zhao et al., Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models, 2026. arXiv: https://arxiv.org/abs/2601.18734 ↩
-
Tianzhu Ye et al., On-Policy Context Distillation for Language Models, 2026. arXiv: https://arxiv.org/abs/2602.12275 ↩
-
OpenClaw-RL Team, OpenClaw-RL: Train Any Agent Simply by Talking, 2026. arXiv: https://arxiv.org/abs/2603.10165 ↩
-
Reinforcement-aware Knowledge Distillation for LLM Reasoning, 2026. arXiv: https://arxiv.org/abs/2602.22495 ↩
-
Self-Distilled RLVR, 2026. arXiv: https://arxiv.org/abs/2604.03128 ↩
-
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, Furu Wei, Black-Box On-Policy Distillation of Large Language Models, 2025. arXiv: https://arxiv.org/abs/2511.10643 ↩
-
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, Ning Ding, Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe, 2026. arXiv: https://arxiv.org/abs/2604.13016 ↩
-
Z.ai / GLM Team, GLM-5: from Vibe Coding to Agentic Engineering, 2026. arXiv: https://arxiv.org/abs/2602.15763 ↩